









Background Summary
For executives, architects, and healthcare leaders exploring AI-powered platforms, this article explains how Inferenz tackled real-time IoT event enrichment challenges using caching strategies.
By optimizing AWS infrastructure with ElastiCache and Lambda-based microservices, we not only achieved a 70% latency improvement and 60% cost reduction but also built a scalable foundation for agentic AI solutions in business operations. The result: faster insights, lower costs, and an enterprise-ready model that can power predictive analytics and context-aware services.-
Overview
When working with real-time IoT data at scale, optimizing for performance, scalability, and cost-efficiency is mandatory. In this blog, we’ll walk through how our team tackled a performance bottleneck and rising AWS costs by introducing a caching layer within our event enrichment pipeline.
This change led to:
- 70% latency improvement
- 60% reduction in DynamoDB costs
- Seamless scalability across millions of daily IoT events
Business impact for enterprises
- Faster insights: Sub-second enrichment drives better clinical and operational decisions.
- Lower TCO: Cutting database costs by 60% reduces IT spend and frees budgets for innovation.
- Scalability with confidence: Handles millions of IoT events daily without trade-offs.
Future-ready foundation: Supports predictive analytics, patient engagement tools, and compliance reporting.
Scaling real-time metadata enrichment for IoT security events
In the world of commercial IoT security, raw data isn’t enough. We were tasked with building a scalable backend for a smart camera platform deployed across warehouses, offices, and retail stores environments that demand both high uptime and actionable insights. These cameras stream continuous event data in real-time motion detection, tampering alerts, and system diagnostics into a Kafka-based ingestion pipeline.
But each event, by default, carried only skeletal metadata: camera_id, timestamp, and org_id. This wasn’t sufficient for downstream systems like OpenSearch, where enriched data powers real-time alerts, SLA tracking, and search queries filtered by business context.
To make the data operationally valuable, we needed to enrich every incoming event with contextual metadata, such as:
- Organization name
- Site location
- Timezone
- Service tier / SLA
- Alert routing preferences
This enrichment had to be low-latency, horizontally scalable, and fault-tolerant to handle thousands of concurrent event streams from geographically distributed locations. Building this layer was crucial not only for observability and alerting, but also for delivering SLA-driven, context-aware services to enterprise clients.
The challenge: redundant lookups, latency bottlenecks, and soaring costs
All organizational metadata such as location, SLA tier, and alert preferences was stored in Amazon DynamoDB. Our initial enrichment strategy involved embedding the lookup logic directly within Logstash, where each incoming event triggered a real-time DynamoDB query using the org_id.
While this approach worked well at low volumes, it quickly unraveled at scale. As the number of events surged across thousands of cameras, we ran into three critical issues:
- Redundant reads: The same org_id appeared across thousands of events, yet we fetched the same metadata repeatedly, creating unnecessary load.
- Latency overhead: Each enrichment added ~100–110ms due to network and database round-trips, becoming a bottleneck in our streaming pipeline.
- Escalating costs: With read volumes spiking during traffic bursts, our DynamoDB costs began to grow rapidly threatening long-term sustainability.
This bottleneck made it clear: we needed a smarter, faster, and more cost-efficient way to enrich events without hammering the database.
Our event pipeline architecture
| Layer | Technology | Purpose |
| Event Ingestion | Apache Kafka | Stream raw events from IoT cameras |
| Processing | Logstash | Event parsing and transformation |
| Enrichment Logic | Ruby Plugin (Logstash) | Embedded custom logic for enrichment |
| Org Metadata Store | Amazon DynamoDB | Source of truth for organization data |
| Caching Layer | AWS ElastiCache for Redis | Fast in-memory cache for org metadata |
| Search Index | Amazon OpenSearch Service | Stores enriched events for analytics |
Our solution: using AWS ElastiCache for read-through caching
To reduce DynamoDB dependency, we implemented read-through caching using AWS ElastiCache for Redis. This managed Redis offering provided us with a high-performance, secure, and resilient cache layer.
New enrichment flow:
- Raw event is read by Logstash from Kafka
- Inside a custom Ruby filter:
- Check ElastiCache for cached org metadata.
- If cache hit → use cached data.
- If cache miss → query DynamoDB, then write to ElastiCache with TTL.
- Enrich the event and push to OpenSearch.
Logstash snippet using ElastiCache
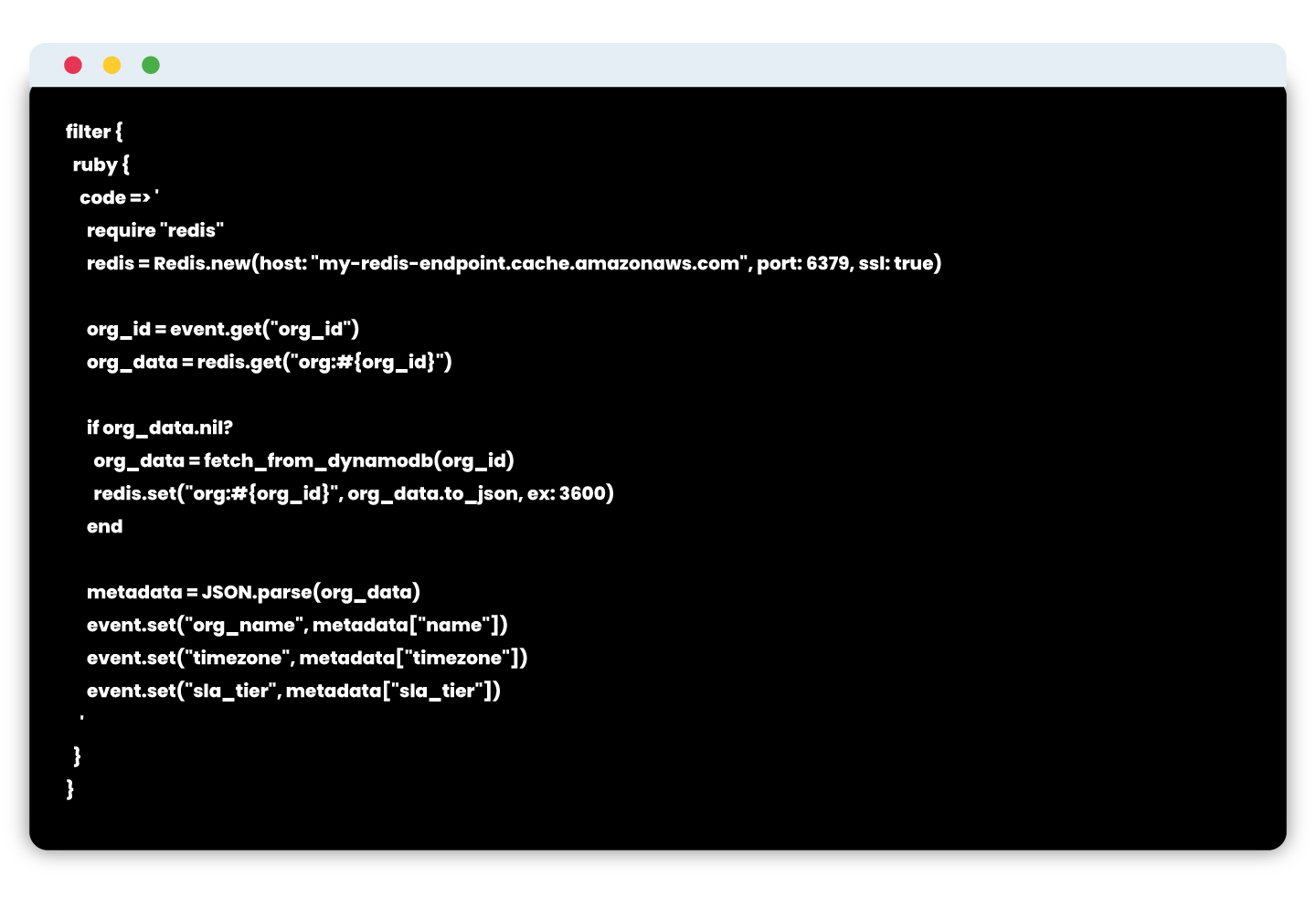
Note: ElastiCache is configured inside a private subnet with TLS enabled and IAM-restricted access.
Results: performance and cost improvements
After integrating ElastiCache into the enrichment layer, we saw immediate improvements in both speed and cost.
| Metric | Before (DynamoDB Only) | After (ElastiCache + DynamoDB) |
| Avg. DynamoDB Reads/Minute | ~100,000 | ~20,000 (80% reduction) |
| Avg. Enrichment Latency | ~110 ms | ~15 ms |
| Cache Hit Ratio | N/A | ~93% |
| OpenSearch Indexing Lag | ~5 seconds | <1 second |
| Monthly DynamoDB Cost | $$$ | (~60% savings) |
Enterprise-grade benefits of using ElastiCache
- In-memory speed: Sub-millisecond access time
- TTL-based invalidation: Ensures freshness without complexity
- Secure access: Deployed inside VPC with TLS and IAM controls
- High availability: Multi-AZ replication with automatic failover
- Integrated monitoring: CloudWatch metrics and alarms for hit/miss, memory usage
Scaling smarter: enrichment as a stateless microservice
As our event volume and platform complexity grew, we realized our architecture needed to evolve. Embedding enrichment logic directly inside Logstash limited our ability to scale, debug, and extend functionality. The next logical step was to offload enrichment to a dedicated, stateless microservice, giving us clearer separation of concerns and unlocking platform-wide benefits.

Evolved architecture:
Whether deployed as an AWS Lambda function or a containerized service, this microservice became the single source of truth for enriching events in real time.
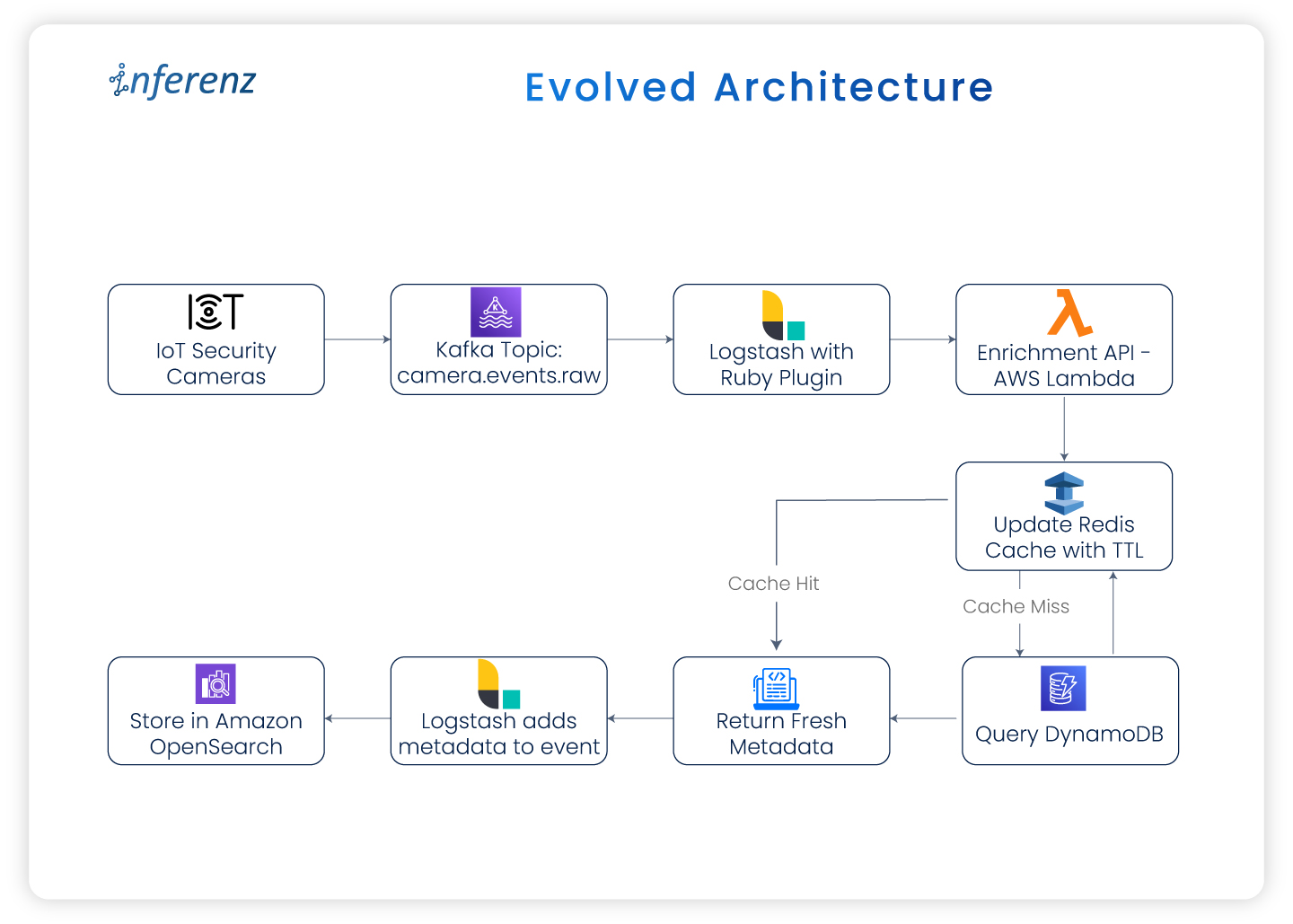
Output flow description:
- Cameras → Kafka
- Kafka → Logstash
- Logstash → AWS Lambda Enrichment
- Lambda → Redis (ElastiCache)
- If cache hit → Return metadata
- If cache miss → Query DynamoDB → Update cache → Return metadata
- Logstash → OpenSearch
Why it worked: key benefits
- Decoupled logic:
By removing enrichment from Logstash, we gained flexibility in testing, deploying, and scaling independently. - Version-controlled rules:
Enrichment logic could now be maintained and versioned via Git making schema updates traceable and deployable through CI/CD. - Reusable across teams:
The microservice exposed a central API that could be leveraged not just by Logstash, but also by alerting engines, APIs, and other consumers. - Improved observability:
With AWS X-Ray, CloudWatch dashboards, and retry logic in place, we had deep visibility into cache hits, fallback rates, and enrichment latency.
Enterprise-grade security & monitoring
To ensure the new design was production-ready for enterprise environments, we baked in security and monitoring best practices:
- TLS-in-transit enforced for all connections to ElastiCache and DynamoDB
- IAM roles for fine-grained access control across Lambda, Logstash, and caches
- CloudWatch metrics and alarms for Redis hit ratio, memory usage, and fallback load
- X-Ray tracing enabled for full latency transparency across the enrichment path
This architecture proved to be robust, cost-effective, and scalable handling millions of events daily with low latency and high reliability.
From optimization to transformation
While caching solved immediate performance and cost challenges, its broader value lies in enabling enterprise-grade AI adoption. By combining IoT enrichment with caching, even healthcare organizations can unlock:
- Predictive patient care (anticipating risks from real-time signals)
- Automated compliance reporting for HIPAA and SLA adherence
- Scalable patient-caregiver coordination through AI-driven scheduling and alerts
This architecture is a blueprint for how agentic AI can operate at scale in healthcare ecosystems.
Conclusion
Introducing caching into the enrichment pipeline delivered more than performance gains. By adopting AWS ElastiCache with a microservice-based model, the system now enriches millions of IoT events with sub-second speed while keeping costs under control. For enterprises, this architecture translates into faster insights for caregivers, stronger SLA compliance, and predictable operating costs.
The design also creates a future-ready foundation for agentic AI in enterprises. Enriched data can now flow directly into predictive analytics, business tools, and compliance systems. Instead of reacting late, organizations can respond to real-time signals with agility and confidence.
At Inferenz, we view caching as a strategic enabler for enterprise-grade AI. It allows security platforms to be faster, more resilient, and prepared for the next wave of intelligent automation.
Key takeaways
- Cache repeated lookups like org metadata to reduce both latency and cloud database costs
- Use ElastiCache as a production-grade, scalable caching layer
- Decouple enrichment logic using microservices or Lambda for better maintainability and control
- Monitor cache hit ratios and fallback patterns to tune performance in production
As your system grows, always ask: “Is this database call necessary?”
If the data is static or semi-static, caching might just be your smartest optimization.

FAQs
Q1. Why is caching so important in IoT event pipelines?
Caching eliminates repetitive database queries by storing frequently accessed metadata in memory. This ensures enriched event data is available instantly, improving response times for alerts, monitoring dashboards, and downstream analytics.
Q2. How does caching support advanced automation in IoT systems?
With metadata readily available in real time, IoT platforms can automate responses such as triggering alerts, updating monitoring tools, or routing events to the right teams without delays caused by database lookups.
Q3. What measurable results did this approach deliver?
Latency improved by 70%, database read costs dropped by 60%, and the pipeline scaled efficiently to millions of daily events. These gains lowered infrastructure spend while delivering faster, more reliable event processing.
Q4. How does the microservice model add value beyond speed?
Moving enrichment logic into a stateless microservice allowed independent scaling, version control, and CI/CD deployments. It also made enrichment logic reusable across other services like alerting engines, APIs, and analytics platforms.
Q5. How is data accuracy and security maintained in this setup?
TTL policies refresh cached metadata regularly, keeping event enrichment accurate. All services run inside a private VPC with TLS encryption, IAM-based access controls, and CloudWatch monitoring for cache performance and reliability.
Q6. Can this architecture support predictive analytics in other industries?
Yes. Once enrichment happens in real time, predictive models can be applied across industries—whether analyzing security camera feeds, monitoring industrial sensors, or tracking retail operations—to anticipate issues and optimize responses.