




Background summary
Hospitals and home-health teams face repeat snags across Patient Access, ED, Inpatient Nursing, Radiology, Peri-op, and more. They face messy referrals and coverage checks, alert noise, heavy charting, imaging backlogs, or delays, medication risks, missed visits, claim denials, and late insight from feedback.
Agentic AI tackles the repeat work behind these issues by reading context, deciding next steps, acting inside your EHR or ERP, and writing back with an audit trail, which speeds flow, reduces errors, and steadies cash. This article maps each department to clear Agentic AI capabilities across departments citing proof points and role-based benefits. -“Keep the lights on, fix the gaps, then let AI take the grunt work.
That quote, shared by a Mid-Atlantic hospital CIO in April, sums up 2025’s mood in health-system IT suites across the U.S. Cost pressure remains high, yet the conversation has moved from whether to apply AI to where first.
Healthcare needs AI implementation, now!
A fresh State of the CIOs survey of 906 healthcare IT leaders puts hard numbers behind the chatter: 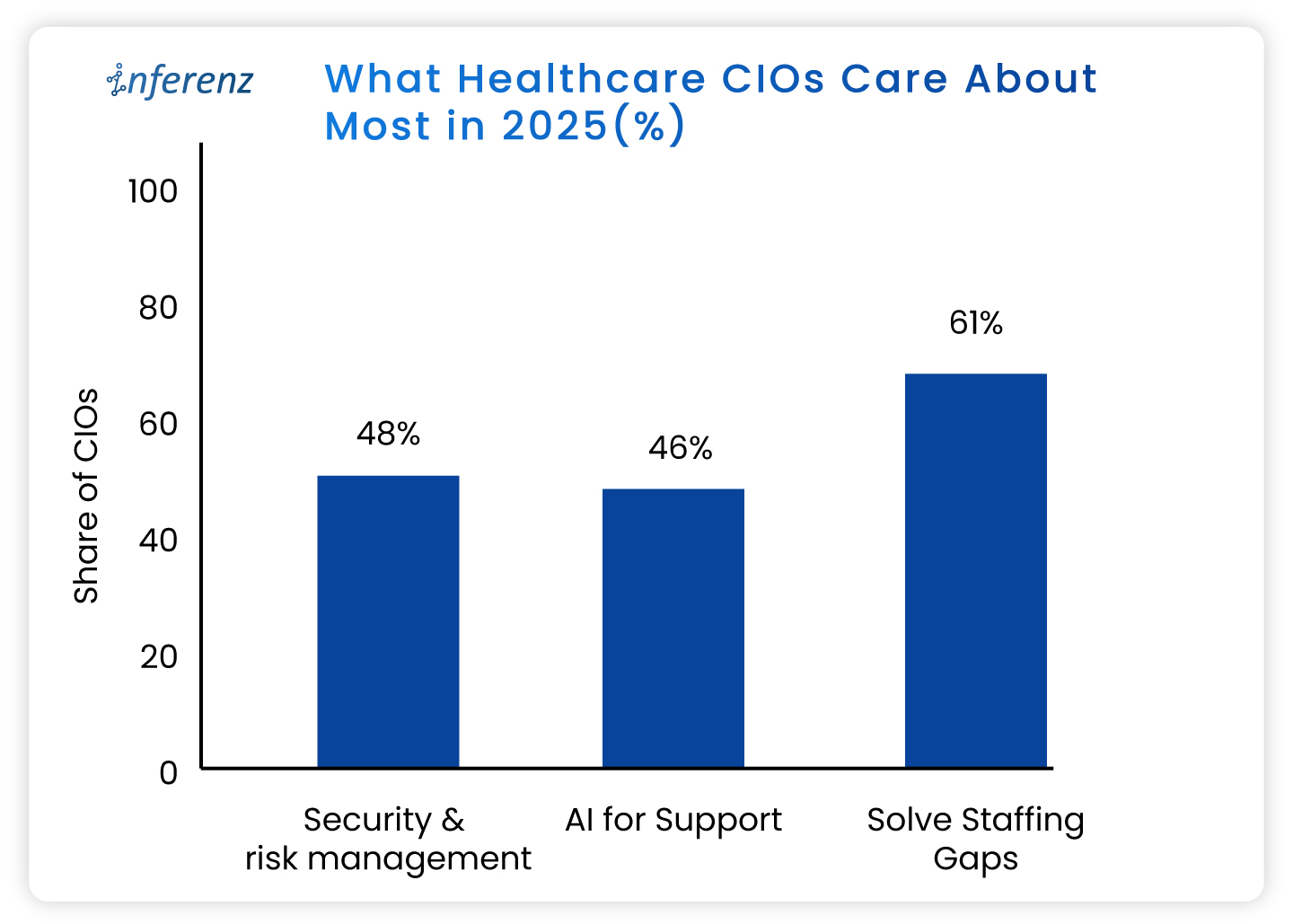
- Solving IT staffing shortages ranks even higher, flagged by 61%.
- Recruiting and keeping skilled people is harder than finding capital.
- AI for support and workflow relief lands at 46 %,
- This trend eclipses past favourites like cloud migrations.
- Security and risk management tops the chart at 48%.
- Ransomware worries still wake leaders at 3 a.m.
What do these healthcare CIO priorities tell us?
- Staffing pressure makes patient access automation urgent, not optional.
- Leaders want bots that shave minutes, not moon-shot labs that promise a payoff five years out.
- AI momentum is practical.
- CIOs are testing agent-based tools inside revenue cycle, nursing rosters, and patient access because those areas pay back in months, not quarters or years.
- Security first means guardrails are non-negotiable.
- HIPAA-compliant AI is a must. The implementations need to comply also with HITRUST, and the new HHS cybersecurity proposals out for comment.
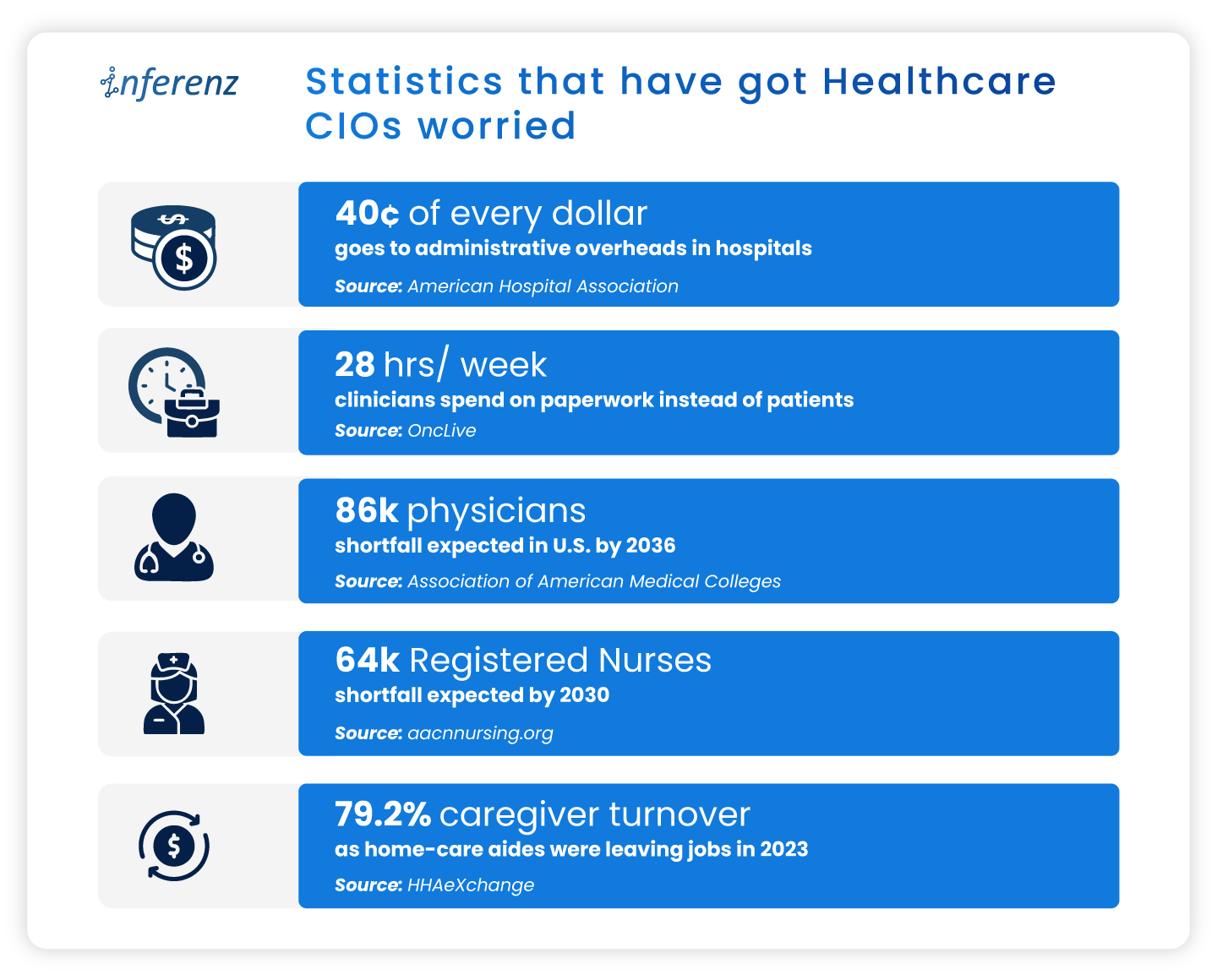
Read more about the top operational issues that have got CIOs worried.
Now that priorities are in place, let us see how agentic AI can help you simplify and enhance your operations.
Agentic AI in healthcare, in full-speed action
Agentic AI work like small digital co-workers that handle repeat work and quick decisions inside your existing systems. Each agent reads context from the EHR or ERP, decides the next step, takes the action, and writes back with a clear audit trail. That is why it fits real operations.
The question is: where do you start?
You start where delays hurt most, set a simple outcome, and let agents carry the routine tasks across three phases of care: Start of Care, Care Delivery, and Post Care. The payoff shows up as fewer handoffs, shorter queues, cleaner data, and faster payment cycles.
Below, we set the context and the core challenge for the major operational areas. Under each, you will see the exact Agentic AI capabilities that meet healthcare AI use cases, using the solution buckets you shared so you can cross-link or pilot right away.
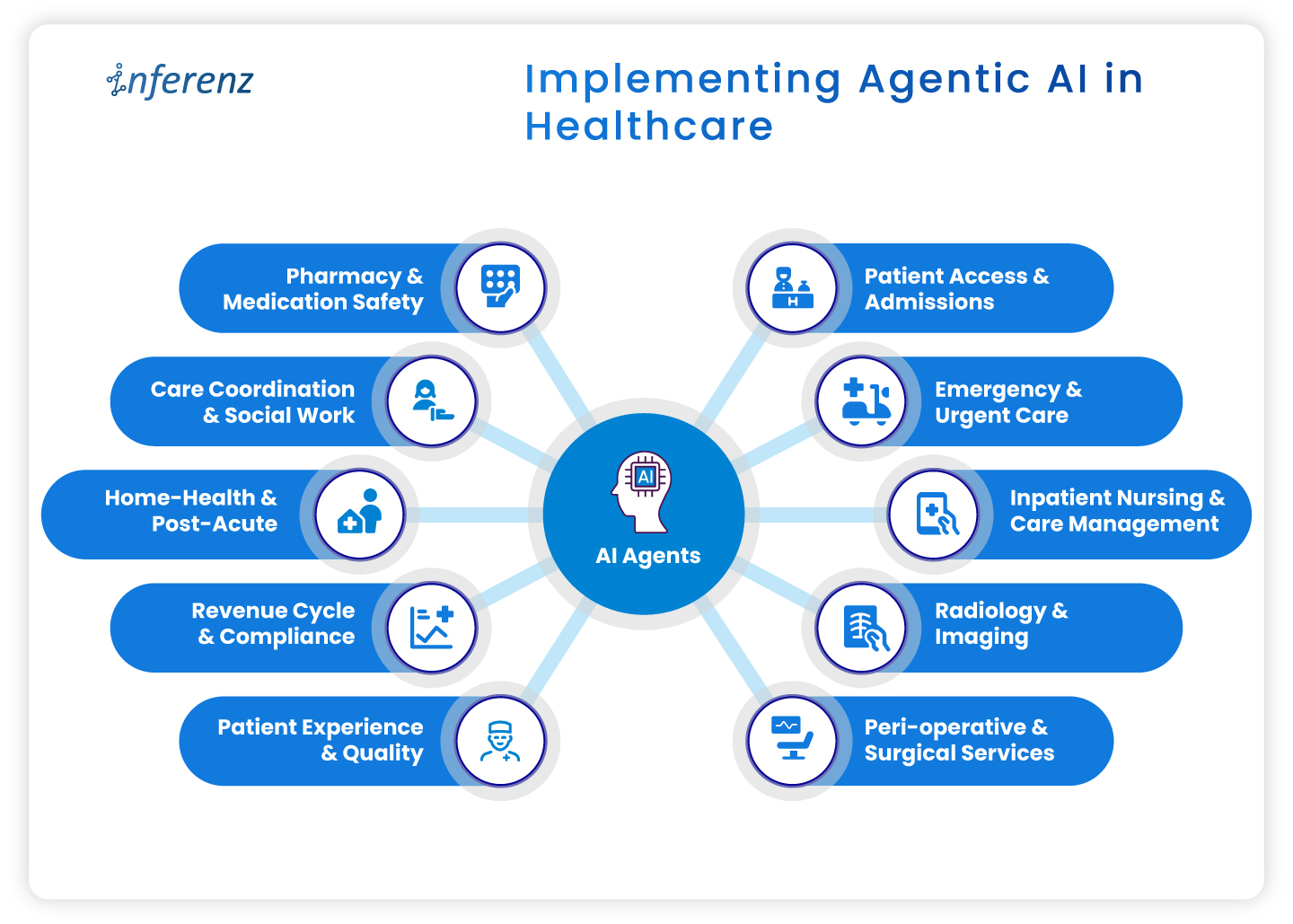 Implementing agentic AI in healthcare
Implementing agentic AI in healthcare
- Patient access & admissions
- Emergency & urgent care
- Inpatient nursing & care management
- Radiology & imaging
- Peri-operative & surgical services
- Pharmacy & medication safety
- Care coordination & social work
- Home-health & post-acute
- Revenue cycle & compliance
- Patient experience & quality
1. Patient access & admissions
Context. Intake teams deal with referrals that arrive in mixed formats, copy data across systems, and chase benefits by phone. Queues grow. First visits slip.
How agentic AI helps.
- Referral & digital intake automation pulls, cleans, and routes referral data into the record.
- Eligibility checks & prior authorization verifies coverage and starts approvals without back-and-forth.
- Patient outreach sends reminders, prep steps, education, and e-consent through the channel patients prefer.
- Digital front desk lets patients book, reschedule, and confirm without a call.
- SDOH analytics flags transport or language barriers early to ease patient onboarding efforts.
- Intake fraud detection prevents duplicate or false identities at the gate.
Operational outcome.
Faster first appointments, fewer re-keyed fields, cleaner claims from day one.
2. Emergency & urgent care
Context. Clinicians need early signal on deterioration. Alert fatigue and manual triage slow action.
How agentic AI helps.
- Active monitoring streams vitals and new labs to an agent that watches for change.
- Alert prioritization filters noise and shows only actionable risks to the right role.
- Clinical risk modeling scores sepsis, readmit, or fall risk in near real time.
- Natural language copilots summarize recent notes so the team sees context on arrival.
Operational outcome.
Faster recognition, fewer false alarms, clearer handoffs.
3. Inpatient nursing & care management
Context. Nurses split time between bedside tasks and documentation. Care plans go stale when conditions shift.
How agentic AI helps.
- Dynamic care plan personalization updates tasks and goals mid-cycle based on new data.
- AI documentation for clinicians drafts visit notes and care plans from voice or short prompts. ICD-10 and HHRG codes are proposed for review.
- Alert prioritization keeps clinicians focused on the few patients who need action now.
- Patient Caregiver Matching to align with patient and caregiver schedules dynamically and intelligently to stay ahead of patient needs.
Operational outcome.
More bedside time, fewer charting hours, faster response on the floor.

[fluentform id=”11″]
4. Radiology & imaging
Context. Studies arrive faster than they are read. Critical cases can wait behind routine ones. Reporting workflows feel heavy.
How agentic AI helps.
- Clinical risk modeling uses order data, vitals, and history to score urgency, so teams handle the right studies first.
- Natural language copilots pre-draft structured impressions from key images and prior reports.
- AI documentation turns dictated notes into clean, compliant reports ready for sign-off.
Operational outcome.
Quicker turnaround, fewer sticky handoffs between techs and readers.
5. Peri-operative & surgical services
Context. Small delays at pre-op and PACU ripple across the day. Discharge notes and coding often lag.
How agentic AI helps.
- Dynamic care plan personalization keeps surgical pathways current from pre-op to recovery.
- Automated discharge & transition summaries create clear handoffs for floor teams and home-health partners.
- Billing/Compliance automation converts post-op documentation into coded encounters and gathers needed attachments.
Operational outcome.
Tighter case flow, on-time handoffs, faster coding after wheels-out.
6. Pharmacy & medication safety
Context. Medication lists change often. Renal function, allergies, and interactions can be missed during rush hours.
How agentic AI helps.
- Clinical risk modeling checks interactions and dose risks against labs and history.
- Natural language copilots summarize med rec and highlight conflicts for pharmacists.
- AI documentation writes structured notes for interventions and education.
Operational outcome.
Fewer preventable events and clearer documentation for audits.
7. Care coordination & social work
Context. Teams try to close loops across clinics, payers, and community partners. Calls and emails eat hours.
How agentic AI helps.
- SDOH analytics surfaces access risks that block progress. A solution like home care analytics works in this regard backed by natural language without dashboards.
- Patient outreach sends targeted messages, education, and transportation prompts.
- Automated follow-up schedules check-ins by protocol and milestone, then tracks responses.
- Feedback mining & sentiment analysis reads messages and surveys to spot issues before they escalate.
Operational outcome.
More completed actions per coordinator and fewer avoidable returns.
8. Home-health & post-acute
Context. Visit schedules, caregiver skills, and travel time rarely align. Drop-offs after week one are common.
How agentic AI helps.
- Patient/Caregiver Matching pairs patients with the right skills and proximity.
- Remote monitoring tracks symptoms or device readings between visits and flags change.
- Automated follow-up sends check-ins and instructions that match the care plan.
- Retention analytics predicts disengagement and suggests outreach that brings patients back.
Operational outcome.
More visits per day, steadier adherence, fewer surprises between appointments.
9. Revenue cycle & compliance
Context. Missing fields and late attachments create denials. Manual status checks slow payment.
How agentic AI helps.
- AI documentation and billing/ compliance automation convert care notes into coded, compliant claims with proofs attached.
- Eligibility checks & prior authorization starts early at intake, then updates status automatically after visits as part of revenue cycle automation.
- Natural language copilots draft appeal letters and collect the right excerpts from the record.
Operational outcome.
Cleaner first-pass claims, fewer reworks, faster cash.
10. Patient experience & quality
Context. Comments from portals, calls, and surveys get scattered. Teams react late.
How agentic AI helps.
- Feedback mining & sentiment analysis aggregates themes and flags risk in near real time.
- Automated discharge & transition summaries set clear expectations and reduce confusion.
- Longitudinal recovery prediction compares recovery against expected trends and signals when to step in.
Operational outcome.
Fewer escalations, clearer communication, tighter loop closure.
Wrap-up
Agentic AI pays off when it sits inside daily work, not beside it. Start with one area where delays or denials sting, choose a small outcome, and pilot the single agent that clears the path. Once the metrics move, extend the same logic to the next step in the care cycle. Hours return to care teams, data gets cleaner, and cash moves faster.
Next step.
If this flow matches your roadmap, you will certainly benefit having a short, printable CIO checklist for use-case selection, data access, privacy controls, success metrics, and for each healthcare department.

[fluentform id=”11″]
Frequently asked questions
1. Where should a CIO start with agentic AI?
Pick one workflow with a clear bottleneck and a single owner. Set one metric, such as first-pass claim rate or ED alert response time, and run a 60–90 day pilot.
2. How does this connect to existing EHRs and ERPs?
Use standard interfaces like FHIR, HL7, and vendor APIs. Keep writes minimal at first, then expand once audit logs and role permissions are proven.
3. What data access is required for a pilot?
Limit to the minimum fields that drive the task. Start with read access and a small write scope, enable full audit trails, and review logs weekly.
4. Is HIPAA compliance realistic with agentic AI?
Yes. Enforce the minimum necessary rule, encrypt PHI in transit and at rest, control access by role, and keep Business Associate Agreements in place.
5. How fast can we see impact?
Most pilots show movement within one quarter if the metric is narrow. Examples include shorter intake time, faster prior auth, or fewer denials.
6. What are the top risks to plan for?
Data quality, alert fatigue, and unclear ownership. Reduce risk with a short pilot scope, clear playbooks, and weekly reviews.
7. How do we prevent biased model behavior?
Test against stratified cohorts, monitor false positives and false negatives by group, and add simple rules that route edge cases to humans.
8. What does change management for AI in healthcare look like?
Train the smallest group that touches the workflow. Use short job aids, shadow support for two weeks, and a clear feedback path to fix snags.
9. How do we choose success metrics?
Tie each agent to a single operational number: minutes saved per referral, prior-auth turnaround, denials per 1,000 claims, or readmission alerts resolved.
10. Do we need a data lake before starting?
No. Start with the systems you have. A lake or Snowflake layer helps at scale, but pilots can work with EHR and ERP feeds.
11. How much does this affect staffing needs?
Agents reduce manual steps and overtime in targeted areas. Use attrition and reassignment rather than broad cuts to maintain buy-in.
12. Can we reuse agents across departments?
Yes. Intake, documentation, and follow-up patterns repeat. Standardize connectors and governance so you can lift and place agents with minor tweaks.

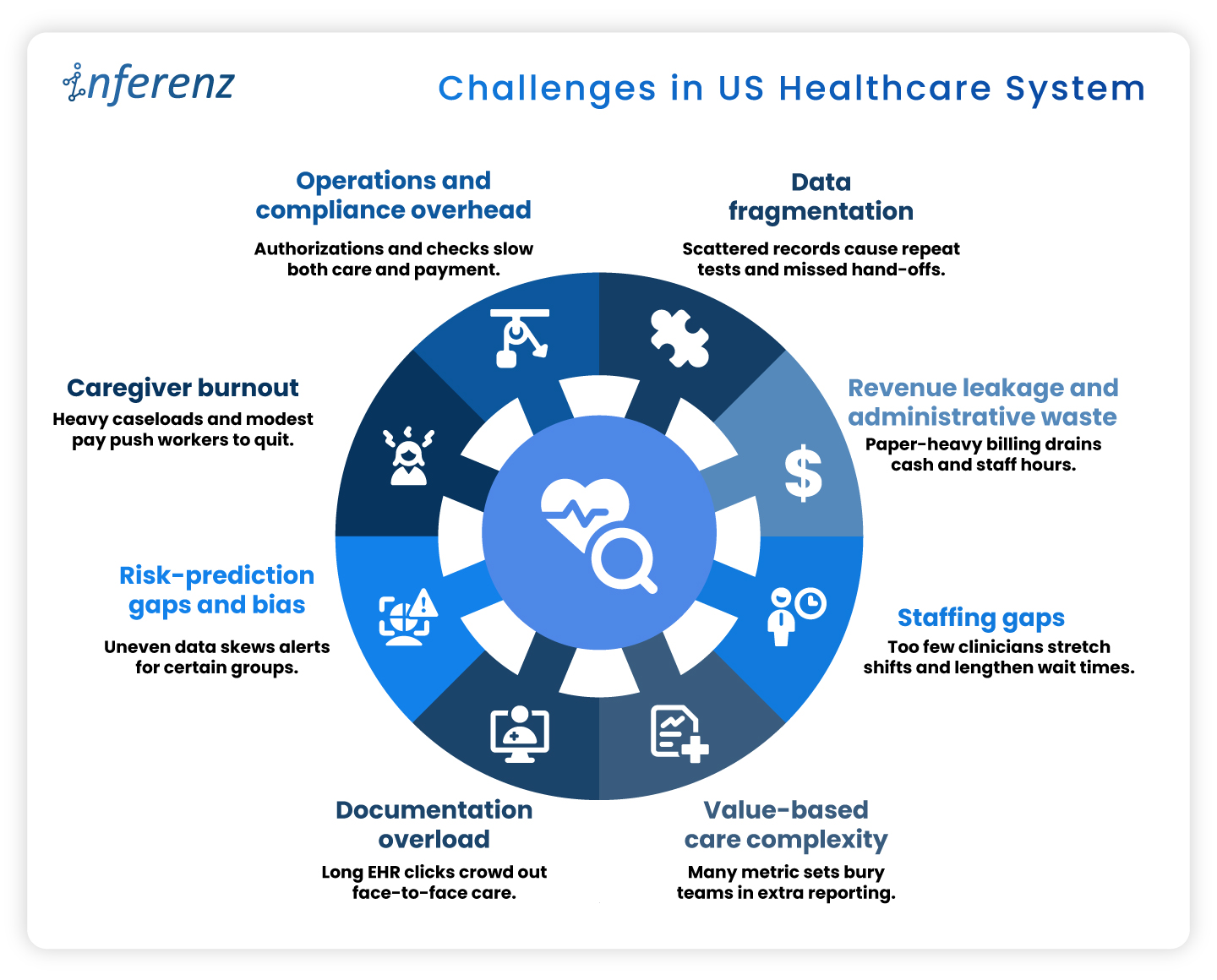




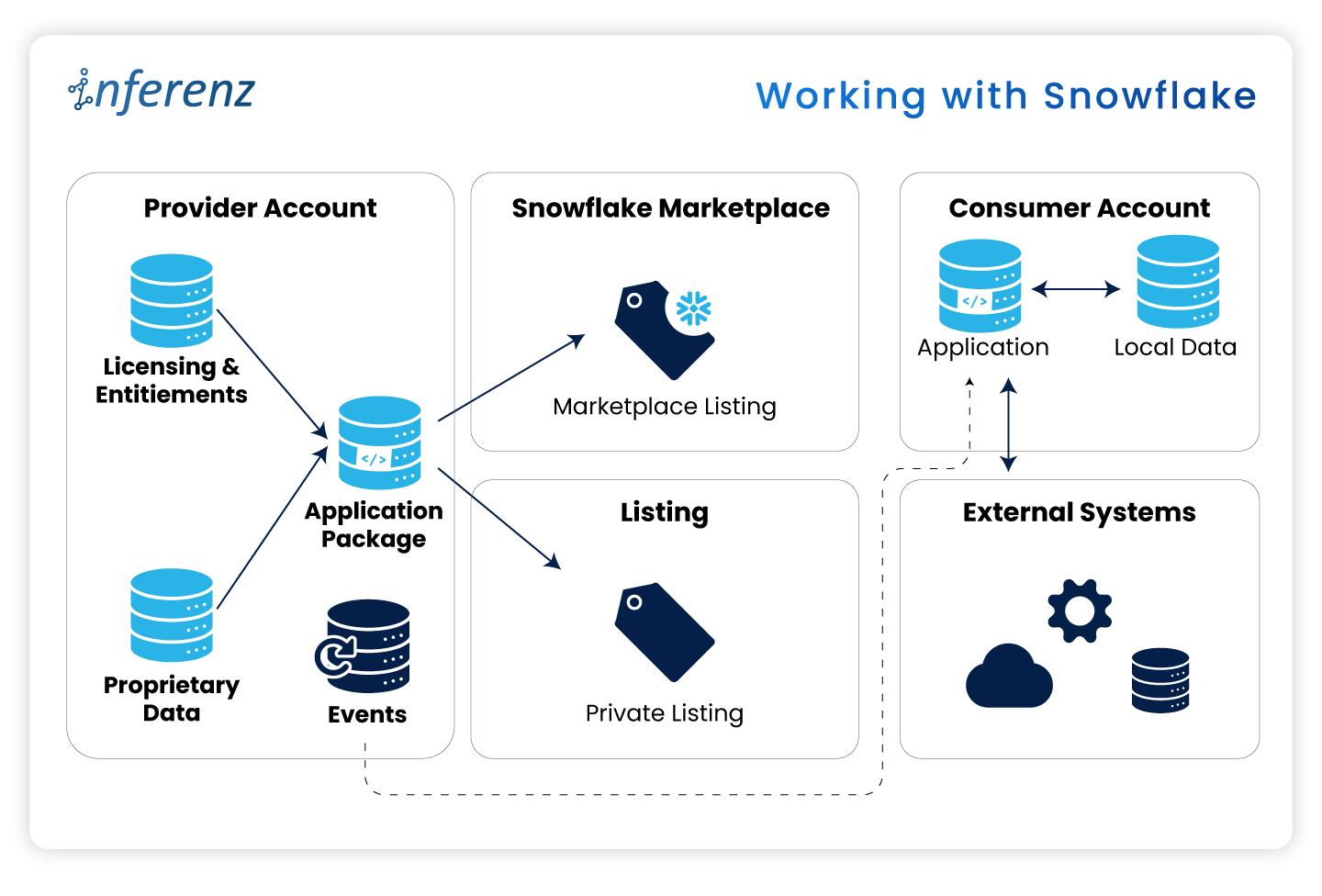
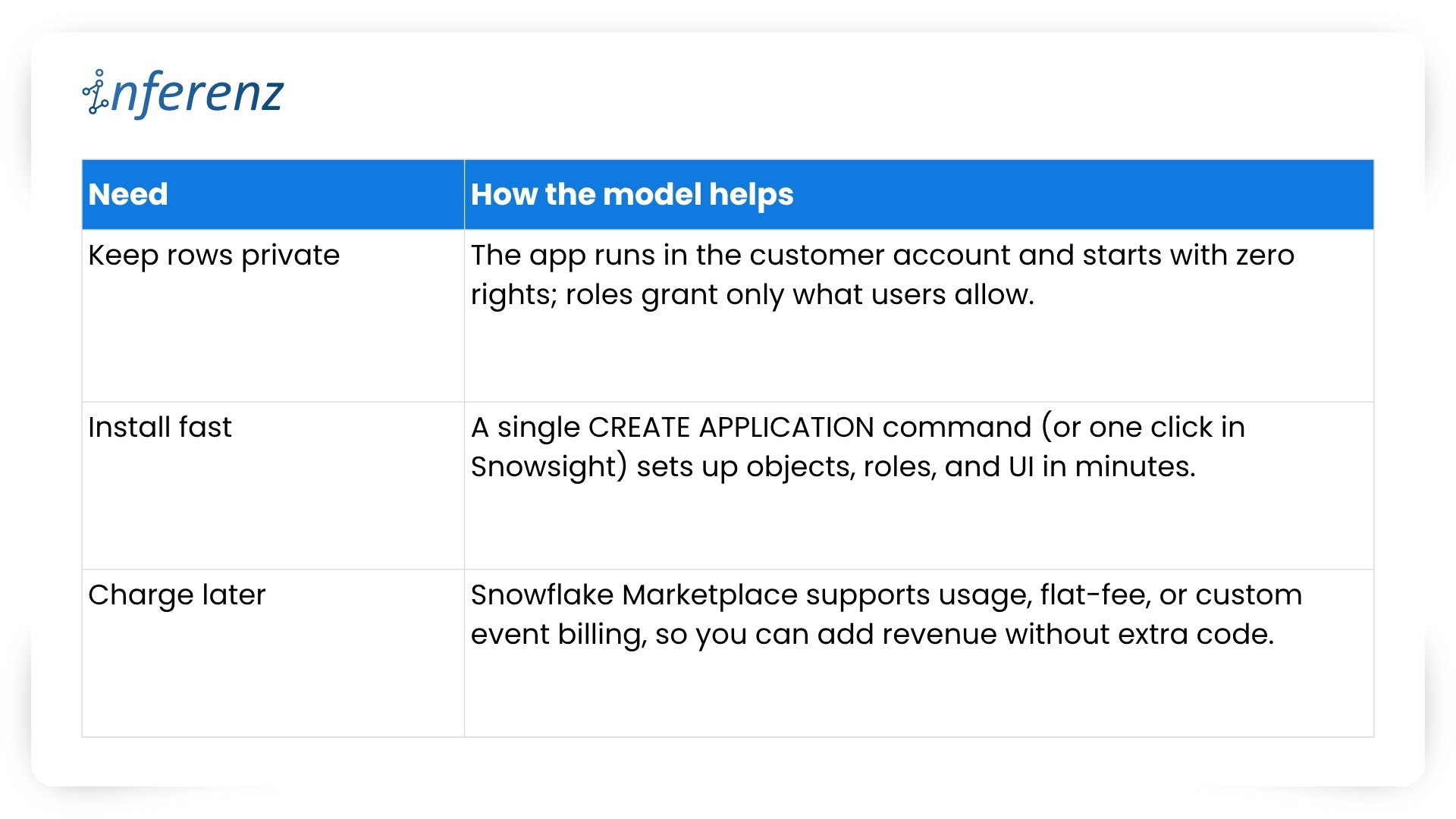




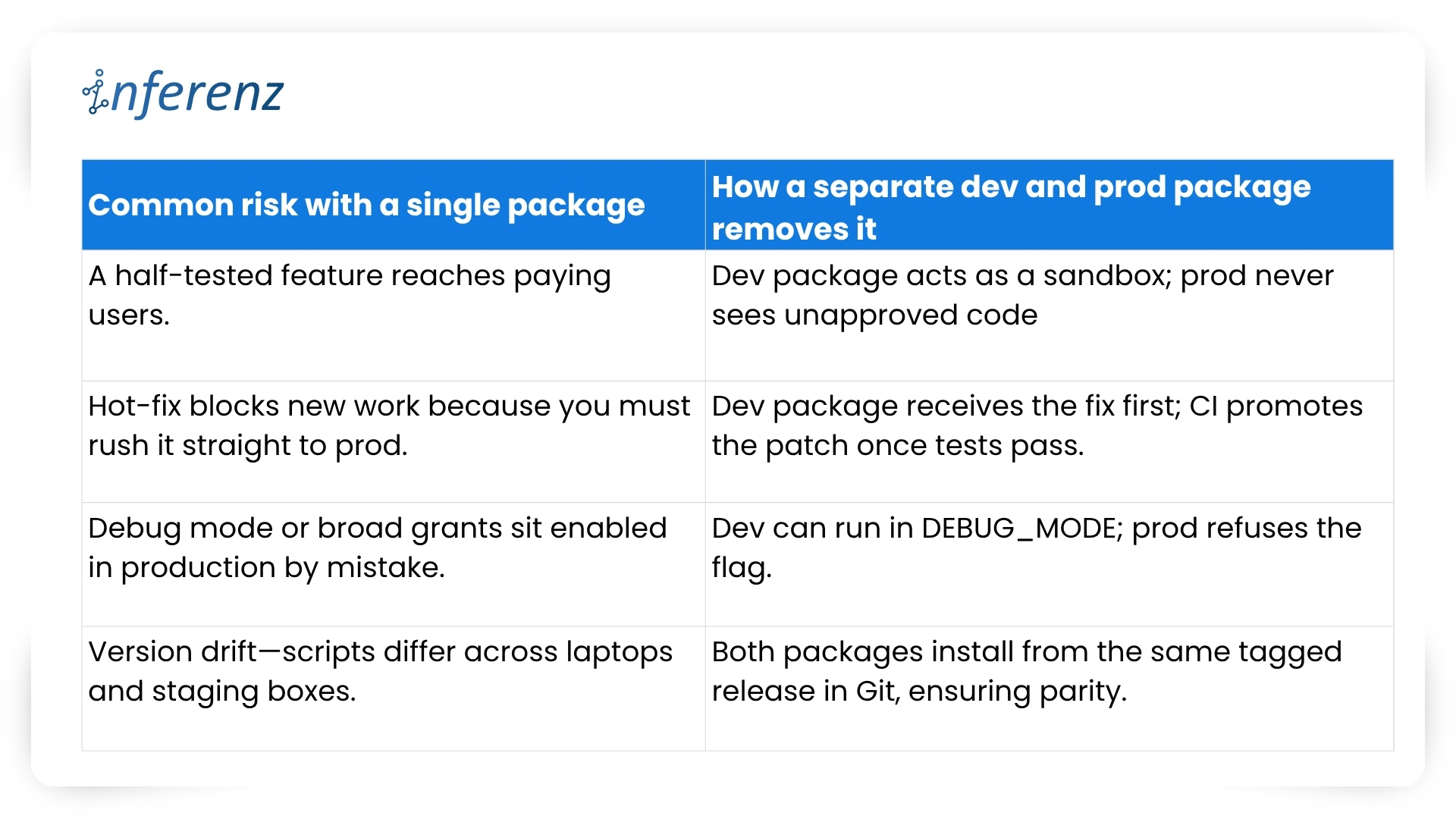
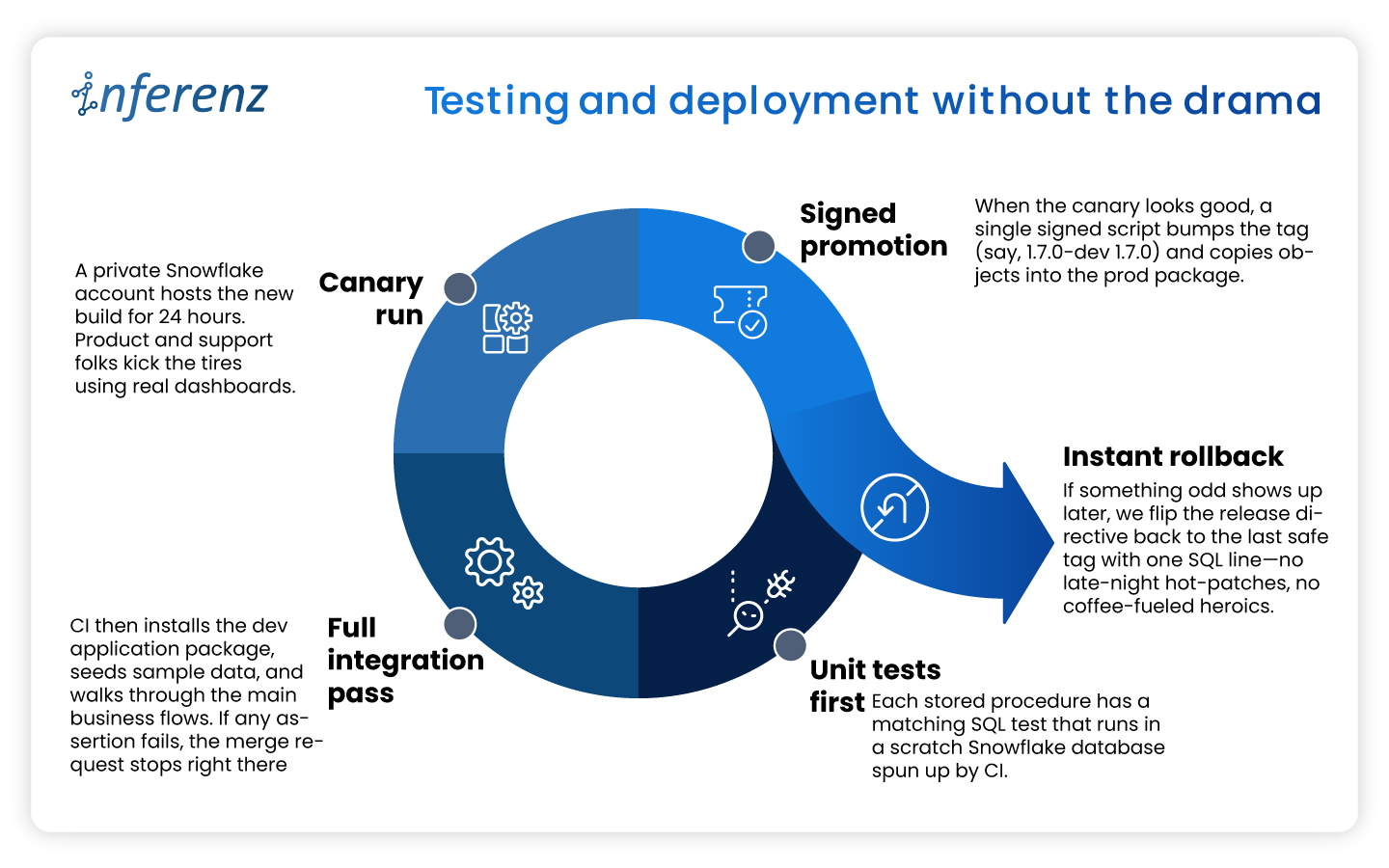





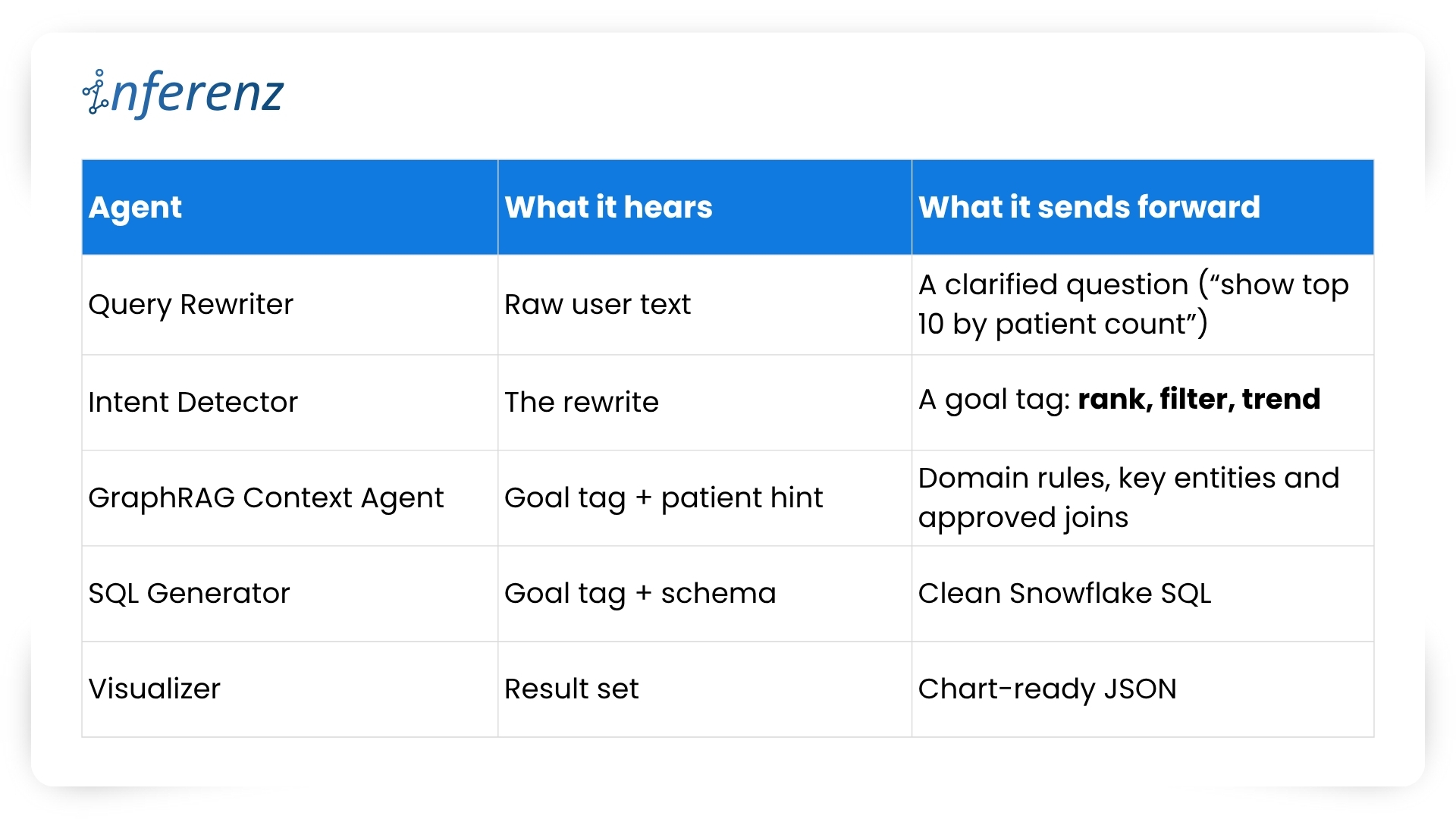 Each agent owns one step. That keeps fixes small and testable.
Each agent owns one step. That keeps fixes small and testable.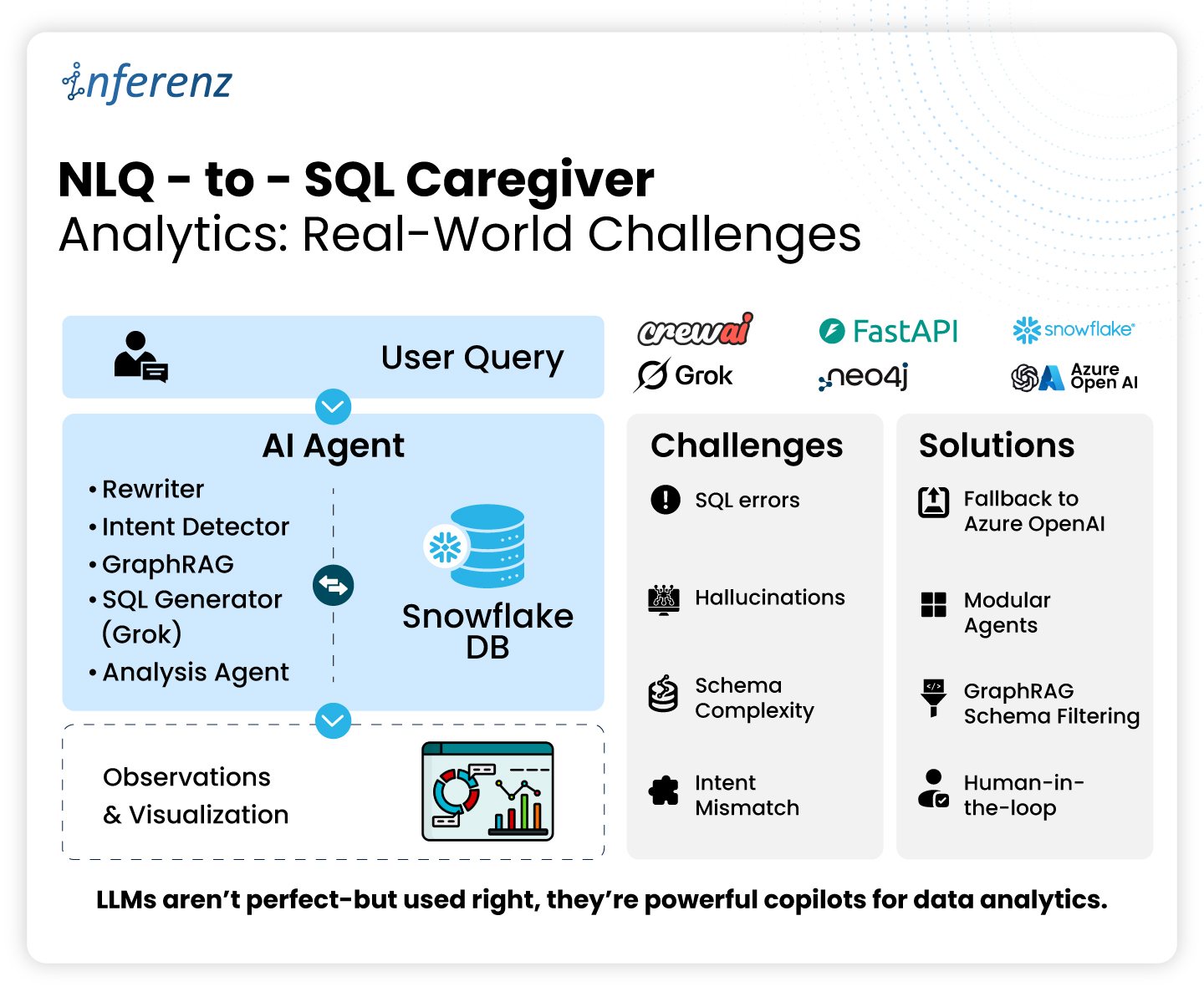



 Poor balance means good aides get overbooked, newer aides sit idle, and both groups start scanning job boards. Until schedules pull live clinical data, automate call-out recovery, and watch workload signals, agencies will keep paying for empty visits and exit interviews.
Poor balance means good aides get overbooked, newer aides sit idle, and both groups start scanning job boards. Until schedules pull live clinical data, automate call-out recovery, and watch workload signals, agencies will keep paying for empty visits and exit interviews. 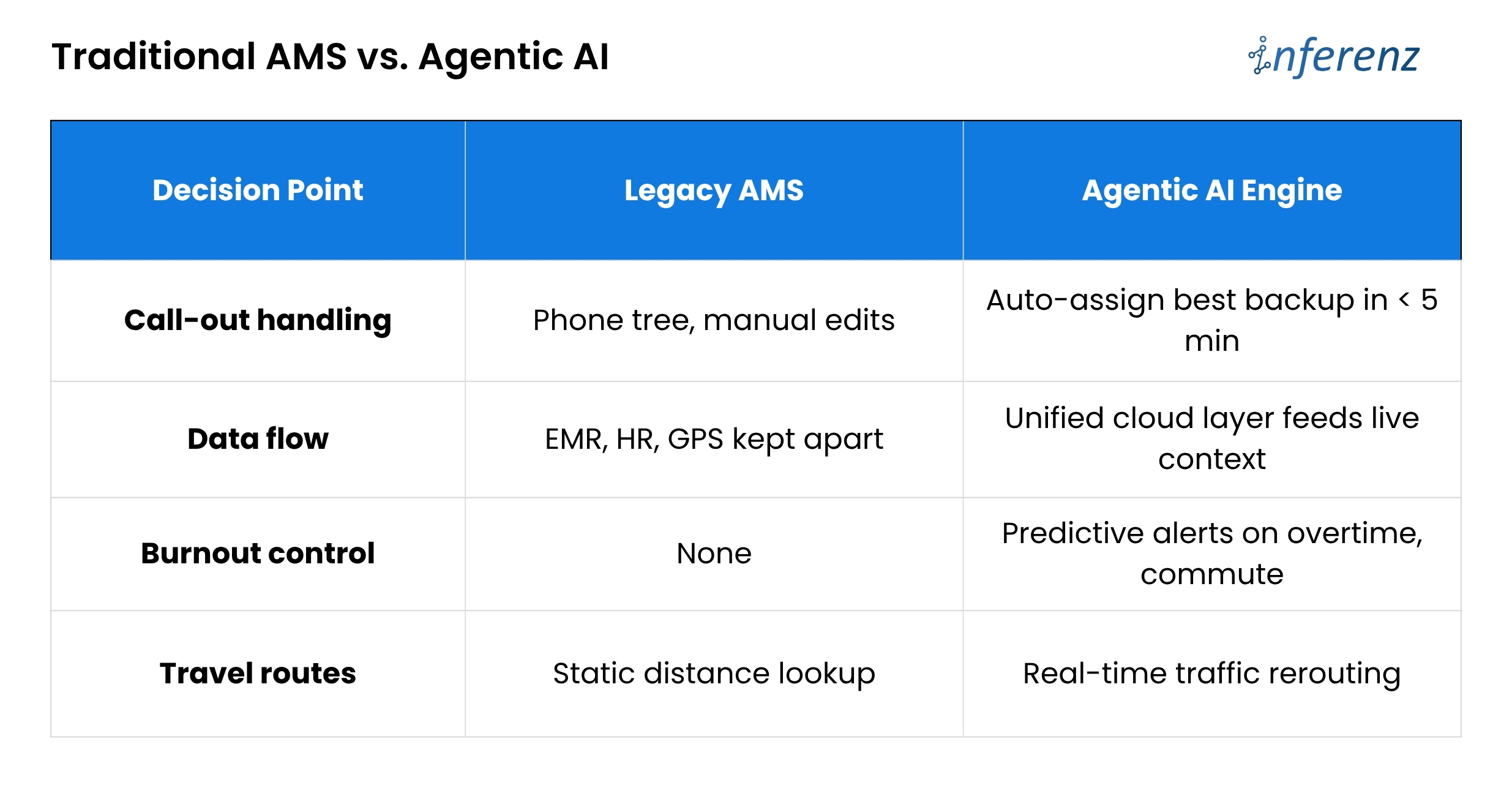 Bottom line:
Bottom line:
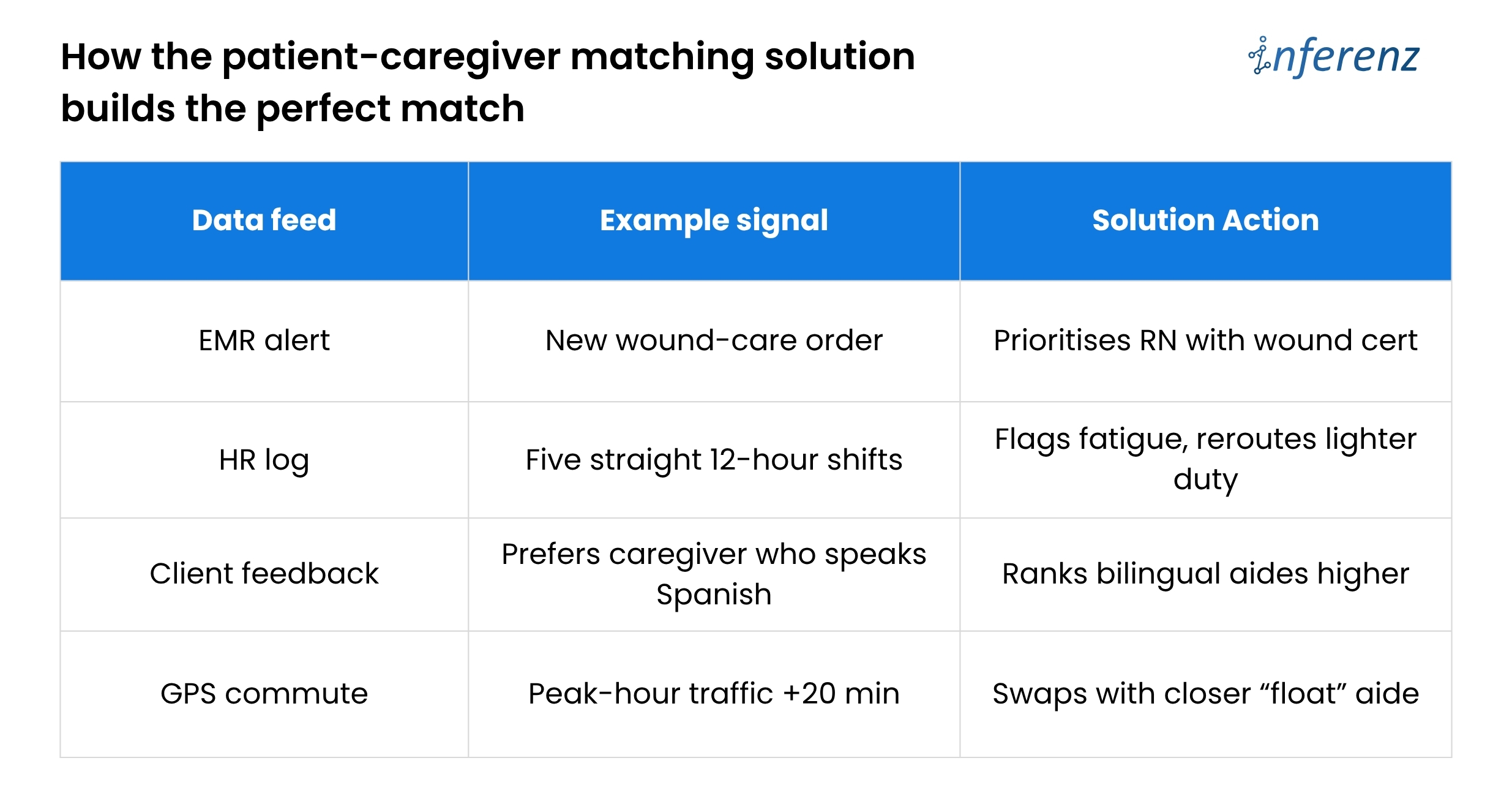

 Home-care agencies lose time and money because scheduling lives in silos. Skills sit in one system, vitals in another, PTO in a third.
Home-care agencies lose time and money because scheduling lives in silos. Skills sit in one system, vitals in another, PTO in a third. 









