

















Summary
Enterprise workspace migration live or die on one thing, whether users trust the new system enough to abandon the old one. This article breaks down a real-world hybrid QA approach that combined manual validation with Python-driven automation to migrate business-critical reports at scale, retire a costly legacy data warehouse, and restore stakeholder confidence through verified numbers.
Introduction
Enterprise migration programs often focus on architecture, timelines, and cutover plans. But in my experience, one question determines whether migration is truly successful:
Do users trust the new system enough to stop using the old one?
That question becomes especially important during data workspace migrations, where dashboards, reports, and operational decisions depend on numbers being correct every single day. legacy
In a recent large-scale migration program, I supported the transition from a enterprise data warehouse to a modernized cloud-based platform, a core part of successful data and cloud modernization initiatives. The backend migration had largely been completed, but many business-critical reports were still tied to the old workspace.
To retire the legacy environment, every report needed to be validated, reconciled, tested, and approved for release.
What made the difference was not choosing between manual testing or automation. It was combining both.
The Real Challenge in Workspace Migration
From the outside, migrations can look straightforward:
- Move tables
- Repoint reports
- Validate numbers
- Go live
In reality, migrations are rarely that simple.
Even after the new platform was built, legacy reports were still actively used by the business. That created several risks:
- Two parallel environments generating similar metrics
- Conflicting numbers across reports
- High support overhead
- Delayed retirement of expensive legacy systems
- Low stakeholder confidence in migrated outputs
The business goal was clear: complete report migration, decommission the old environment, and ensure zero disruption to reporting operations.
That required a strong QA strategy.

Why Manual Testing Came First
Before introducing automation, manual validation covered key metrics including revenue, headcount, and quantities sold. Historical outputs were compared across six years of data, from 2019 through 2025, for approximately 80 active parks to understand data patterns, business rules, and known exceptions.
This step was non-negotiable.
Automation is powerful. But it should not be the first move when system logic is still being understood. Manual testing answered the questions automation cannot ask on its own:
- Which source should be treated as authoritative?
- Were variances caused by logic changes or bad data?
- Were filters, joins, or calculations inconsistent across reports?
- Did report visuals reflect correct backend totals?
Without this phase, automation would have scaled confusion faster
When Legacy Data Isn’t the Source of Truth
One of the most important discoveries during testing was that the legacy warehouse was not always correct.
Initial reconciliation between the old and new platforms showed mismatches in revenue and other KPIs. Since the business had relied on the legacy environment for years, it was assumed to be the benchmark.
However, I extended validation to compare the new warehouse against the operational source system.
That independent source confirmed the modern platform was producing the correct results.
This changed the migration narrative entirely.
The question shifted from:
“Why doesn’t the new system match the old one?”
to:
“How quickly can we transition to the accurate system?”
This is where QA becomes more than testing. It becomes a trust-building function.
Scaling with Python Automation
Once the business rules were validated manually, I designed an automation framework using Python, Selenium, SQL, and Excel reporting to reduce repetitive reconciliation effort, similar to other config-driven data automation implementations built for scalable enterprise workflows.
Before Automation vs. After: The Process Comparison
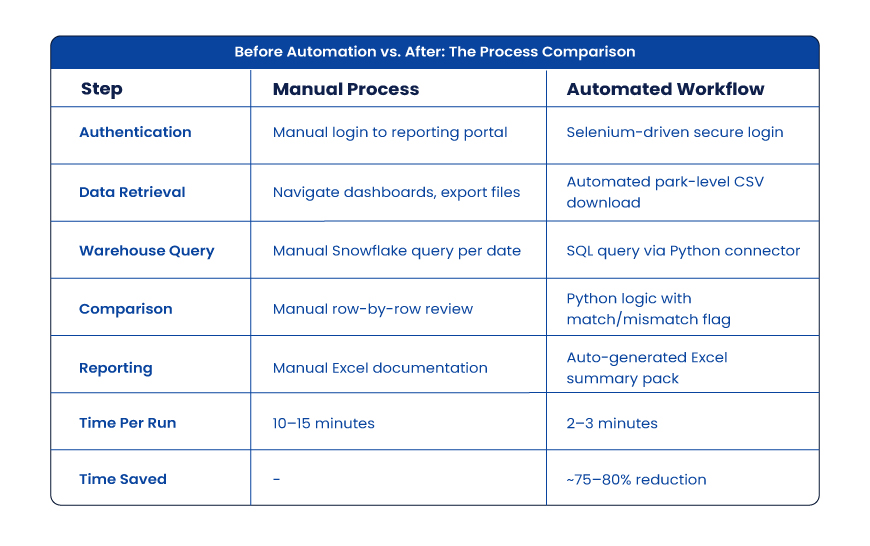
That speed gain allowed more frequent checks, faster defect isolation, and stronger release readiness.
Automation Delivers Leverage
Once metric logic and report behavior are understood, automation becomes a force multiplier.
In this program, I designed Python-based validation workflows integrating multiple technologies:
- Python for orchestration and comparison logic
- SQL for warehouse reconciliation
- Snowflake for source/target metric extraction
- Selenium for controlled portal interactions and report retrieval
- GitHub for version control and maintainability
- Excel outputs for business-readable evidence packs
This hybrid model reduced repetitive reconciliation cycles dramatically while improving repeatability.
Instead of spending analyst time re-running the same checks manually, teams could focus on exceptions, defects, and release readiness. This is where intelligent automation solutions deliver measurable business impact by eliminating operational friction while improving accuracy.
That is where automation creates strategic value-not replacing testers, but removing waste.
Business Impact Beyond Speed
Across the migration program:
- 19 reports completed, with remaining reports progressing through the pipeline
- 75 defects identified and corrected
- Zero rebuttals raised against QA findings
- SIT to UAT movement became measurably more efficient
- Stakeholder confidence improved at the executive level
Most importantly, the organization moved closer to retiring its costly legacy environment and realizing the full ROI from its modern data platform investment.

Why Manual + Automation Is the Winning Formula
Many teams frame this as a binary choice – manual testing or automation, human expertise or scripts. In migration programs, that framing is the problem.
The strongest model runs both tracks in sequence:
- Manual Precision handles understanding business logic, exploratory testing, edge-case analysis, user acceptance readiness, and data trust validation.
- Automated Scale handles repeatable reconciliation, regression testing, high-volume comparisons, faster feedback cycles, and continuous confidence checks.
One provides judgment. The other provides speed. You need both, and in that order.
Final Thoughts
Workspace migrations succeed when users confidently stop looking back.
That confidence does not come from architecture diagrams or project plans alone. It comes from proven numbers, tested reports, and reliable validation frameworks.
As QA professionals, our role is no longer just finding defects at the end.In modern migration programs, we help organizations move forward with certainty.And that starts with manual precision, backed by automated scale.
Frequently Asked Questions
1. What is a hybrid QA strategy in data warehouse migration?
A hybrid QA strategy pairs manual testing for business logic discovery with automated testing for high-volume reconciliation. Manual catches edge cases early; automation scales validated checks across reports. The result: faster data migration QA with fewer defects and stronger stakeholder confidence.
2. When should you start automating QA during a migration project?
After manual validation confirms your source of truth, business rules, and pass/fail criteria. Automating before that foundation exists scales bad assumptions. Most enterprise data migration programs need 2–4 weeks of structured manual testing before the first automation script runs.
3. How do you resolve discrepancies between a legacy system and a new platform?
Introduce a third reference: the operational source system. If the new platform matches it and the legacy warehouse doesn’t, the legacy system is wrong. This independent validation approach accelerates stakeholder buy-in and clears the path to cutover faster.
4. What tools are used in automated QA for data migration testing?
The most common stack: Python (orchestration), SQL (reconciliation queries), Snowflake (cloud warehouse extraction), Selenium (portal automation), GitHub (version control), and Excel (stakeholder reporting). Together, they cover most enterprise migration QA use cases end to end.
5. How does migration QA impact AI-driven analytics and AIOps pipelines?
AI models queried against migrated data inherit any undetected errors from the migration layer. A rigorous QA framework, especially one validating multi-year historical data against source systems, reduces hallucinated insights in downstream AI tools. Clean migration data is the prerequisite for trustworthy AI outputs.




