Summary
Hospitals have a complete electronic health record, but two gaps remain: data scattered across multiple source systems, and work that nothing acts on. This piece lays out a two-layer fix: a governed healthcare data platform and a no-code agentic AI layer, joined by one conversational interface, built on the systems a hospital already owns.
A decade of investment made the electronic health record the undisputed system of record. Whether the platform is Epic, Oracle Health, MEDITECH, or another major EHR, the chart is complete.
That was the achievement of the last era. It is also its ceiling; for two reasons every CIO, CMIO, and informatics leader feels daily.
First, the EHR was never the whole picture.
The record sits alongside laboratory, imaging, pharmacy, revenue cycle, coding, bed management, an ERP, a patient portal, health-information exchange, and a stream of device data – and, across a real health system, post-acute and community systems too. Some are modules of the EHR; many are separate, and true healthcare interoperability across them is rare. None, alone, tells the full story of a patient or a service line, and manual healthcare data integration, stitching records together by hand, is where reliable insight goes to die.
Second, the EHR records work but rarely does it.
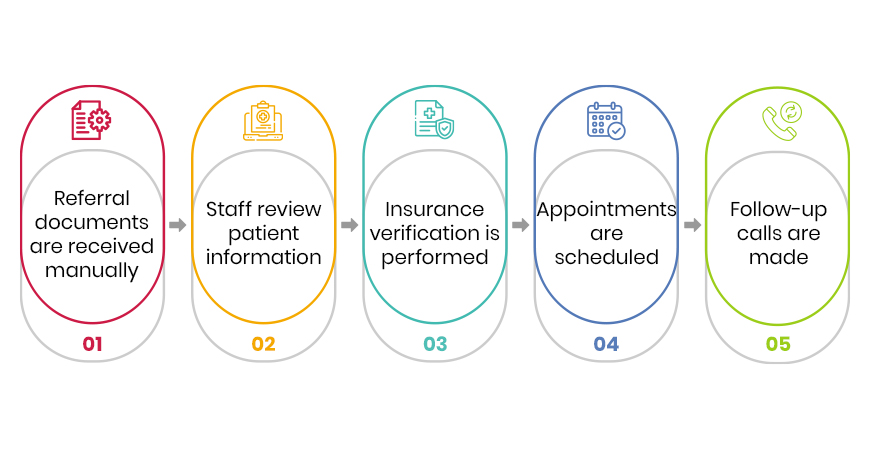
Between the records sits an enormous layer of human effort: reading a referral and keying it in, chasing a prior authorization, reconciling a document, following up on an order, moving a patient through the building and out to the next setting of care.
The chart captures the result. But it performs almost none of the labor.
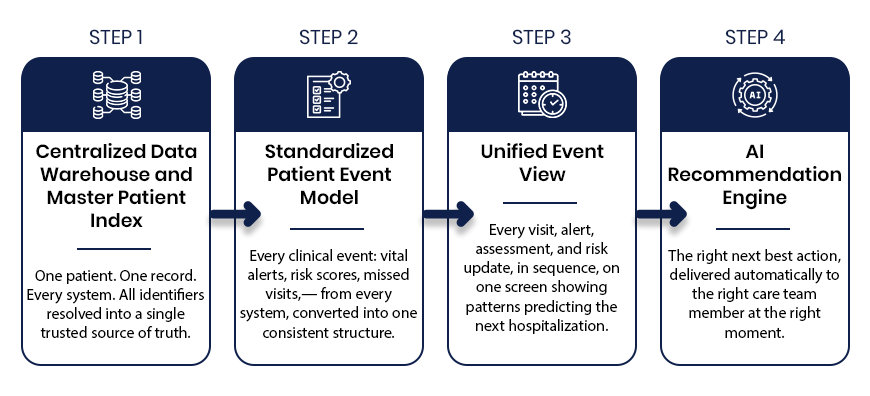
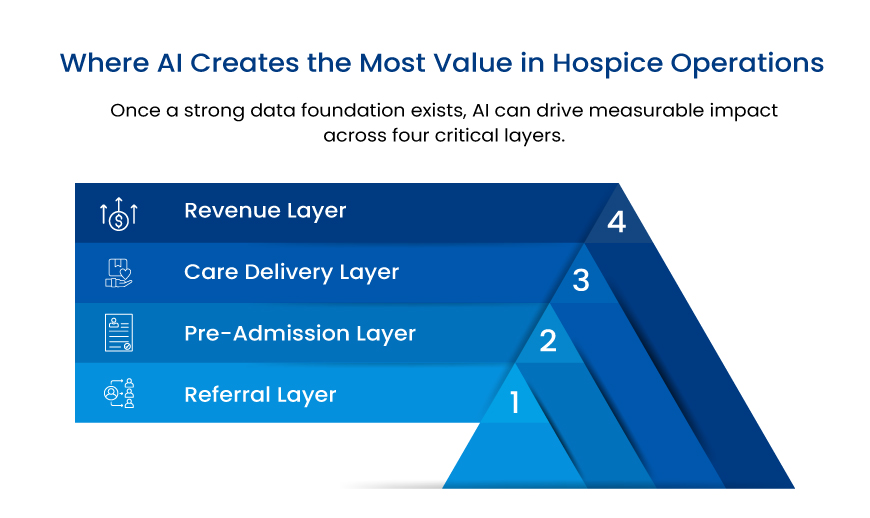
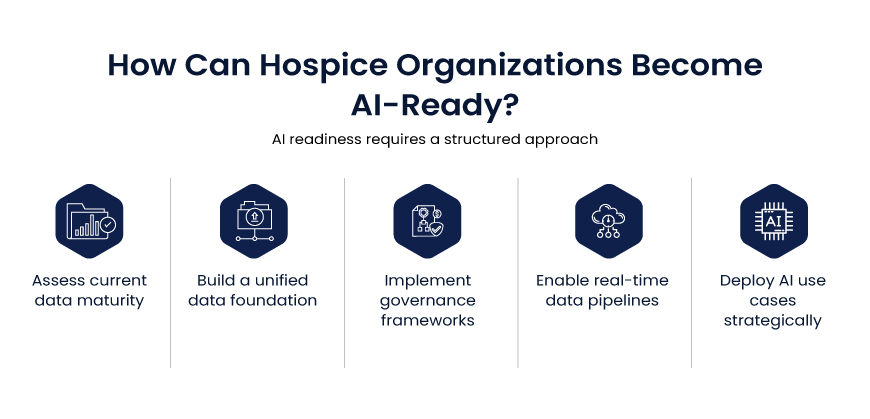
So, the modern hospital carries two structural gaps: data it cannot see whole, and work nothing acts on. The AI-ready hospital closes both, in order, without touching the EHR it depends on.
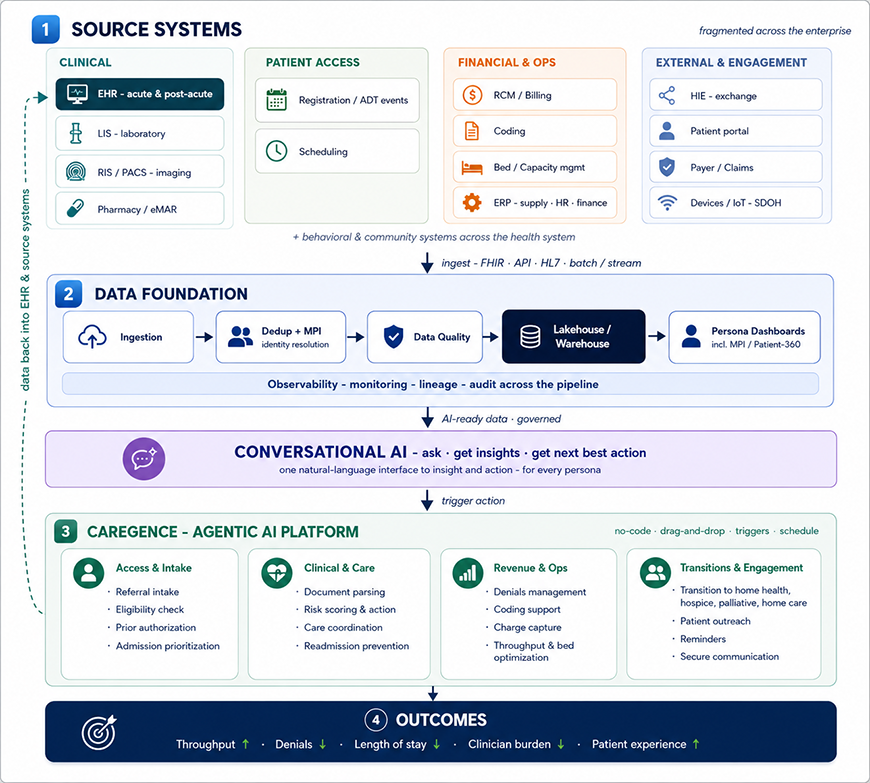
Three layers over the systems you already own, joined by one conversational interface. Data flows up into the foundation; a natural-language assistant turns it into insight and next best actions; the agentic AI layer executes and writes back into the EHR and source systems for continuous EHR data integration, signifying a closed, observable loop.
Layer one: a healthcare data platform that makes data whole
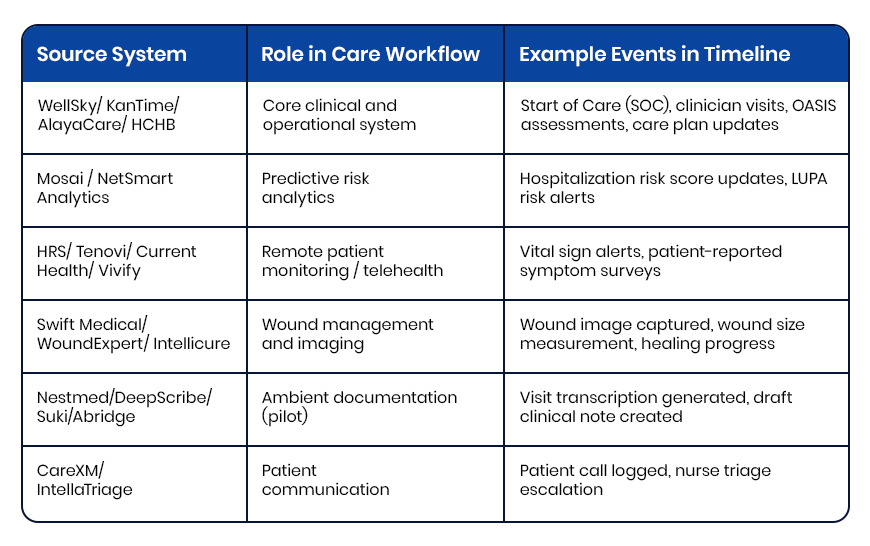
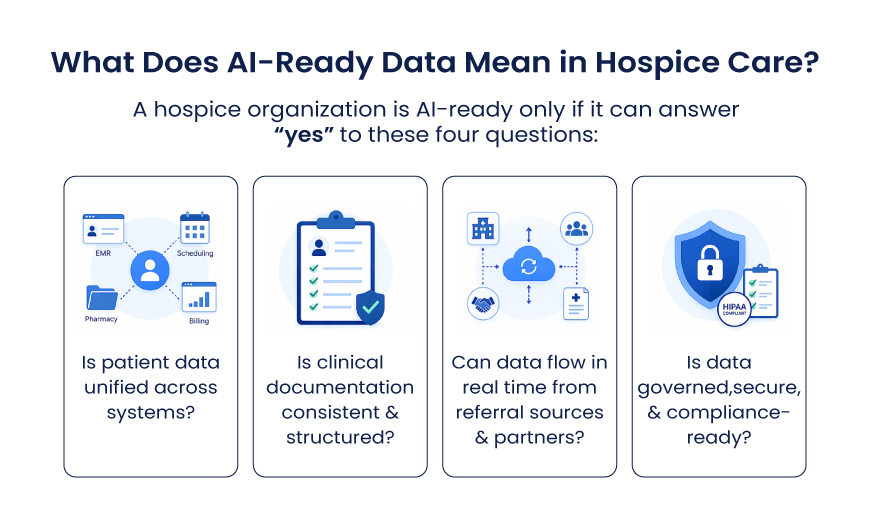
Before any AI is trustworthy, the data must be. The foundation ingests from every source: clinical, financial, operational, external, and the post-acute and community systems in the health system. It uses FHIR where it exists, native APIs where it does not, and HL7 where it must.
It resolves duplicate identities into a single master patient index, the foundation of a true Patient 360 view, enforces data quality and healthcare data governance, and lands everything in a governed lakehouse-warehouse, with observability across the whole pipeline. What leaders see is not raw plumbing but persona-specific dashboards, an operations view for the CIO, a clinical view for the CMIO, a service-line view for the leader who owns the P&L, including a unified Master Patient Index / Patient-360 view that finally shows one patient as one record.
The way in with conversational AI
Dashboards answer the questions you already know to ask. A hospital needs more than that. So, the foundation and the agentic layer share one conversational AI interface built for healthcare teams: ask a question in plain language, get an insight drawn from your own data, and get the next best action – which the platform can then carry out. A service-line leader can ask why to length-of-stay drifted last month; a case manager can ask which discharges are highest-risk today and set the follow-up in motion. One way in, for every persona.
Layer two: agentic AI that acts
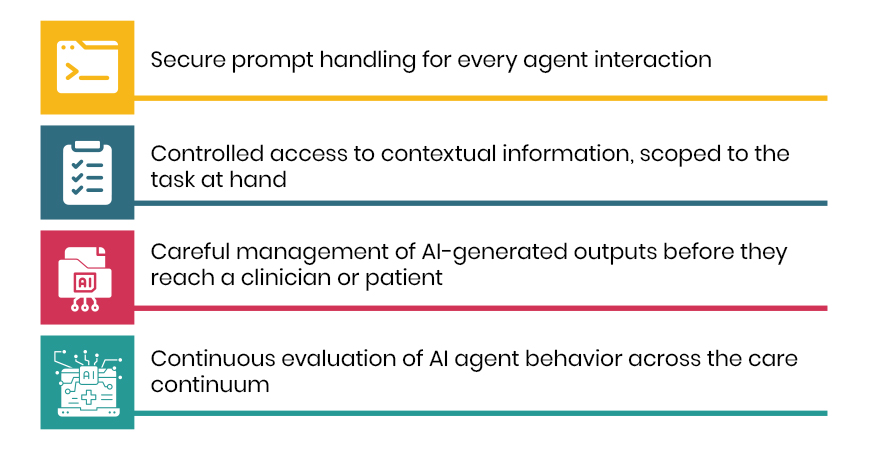
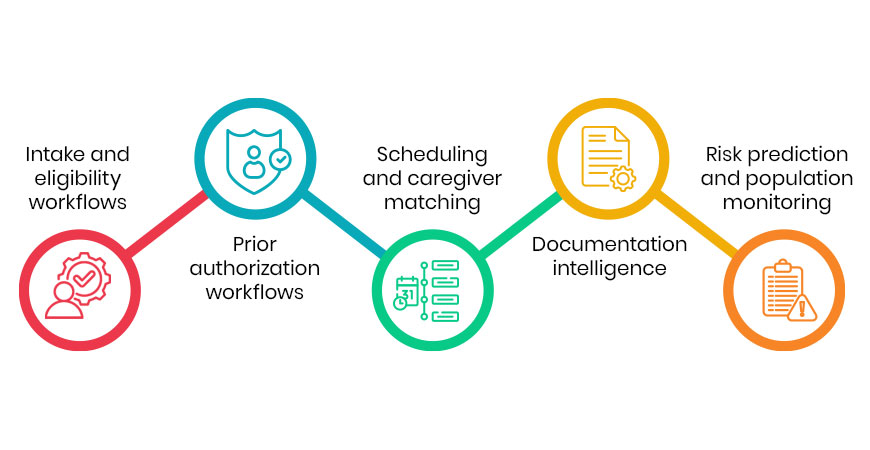
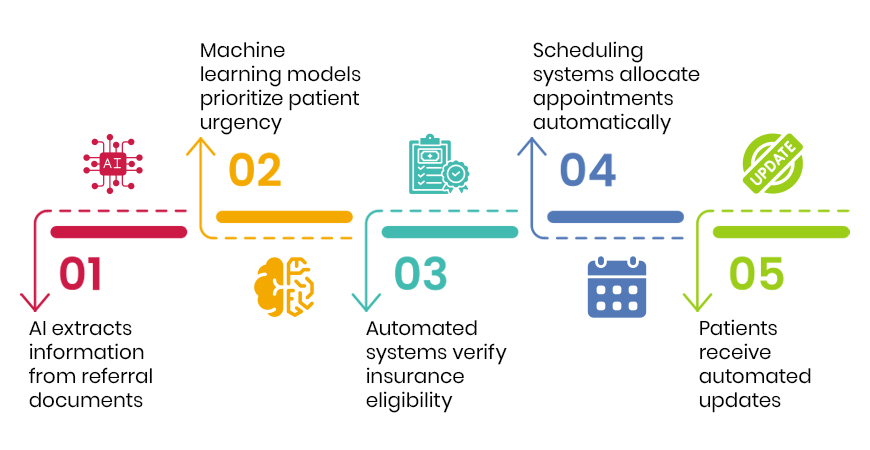
On that foundation, a no-code orchestration platform for agentic AI in healthcare turns the record into action across the care continuum and the back office alike: automating access and intake – including prior authorization automation, supporting clinical work and care coordination, tightening revenue and operations with denials management software and coding support, and engaging patients directly. Workflows are built by drag-and-drop, run on schedules or event triggers, and every action is logged, observable, and written back into the EHR and source systems, so the system of record stays current while the work finally gets done.
The step most hospitals still do manually; the transition out
One use case deserves singling out, because it sits at the boundary of the hospital’s control and its accountability: the transition of care at discharge. Referrals to home health, hospice, palliative care, and home care are still largely faxed, keyed, and sent into the dark, even as readmissions and value-based contracts make what happens next the hospital’s problem. Automating that hand-off, and monitoring risk after it closes the seam between the hospital and the next setting of care.
Keep your EHR. Add the three things it was never built to be: whole, conversational, and active.
Why AI stalls without these layers
- Fragmented data, unreliable AI. Models built on scattered, duplicated, uneven data cannot be trusted, and leaders know it, so nothing ships.
- A high safety bar, rightly. HIPAA, clinical risk, and audit obligations make automation without governance and observability a non-starter.
Every layer here is additive. None disrupts the EHR. That is what makes the path realistic for a live health system rather than a slide.

Where Inferenz stands
We are a healthcare-native Data & AI company driving healthcare workflow automation, building these layers is what we do. Three things let us do it quickly and safely:
- Proven delivery for healthcare. We design, build, and run production data platforms and AI for healthcare organizations unifying dozens of source systems into a single source of truth, master data and patient indexing, predictive risk models, conversational AI assistants, and agentic workflows.
- Partnerships that de-risk the platform. Deep partnerships and alliances with Databricks, Snowflake, Azure, and AWS mean the foundation runs on the cloud and data platforms your teams already trust – no exotic stack to maintain, and a clear path to scale.
- Accelerators and frameworks that compress time-to-value. A library of 30+ production accelerators: ingestion, deduplication, data quality, observability; a lakehouse-warehouse blueprint; a Master Patient Index; and pre-built Caregence tools, turns months of build into weeks of configuration.
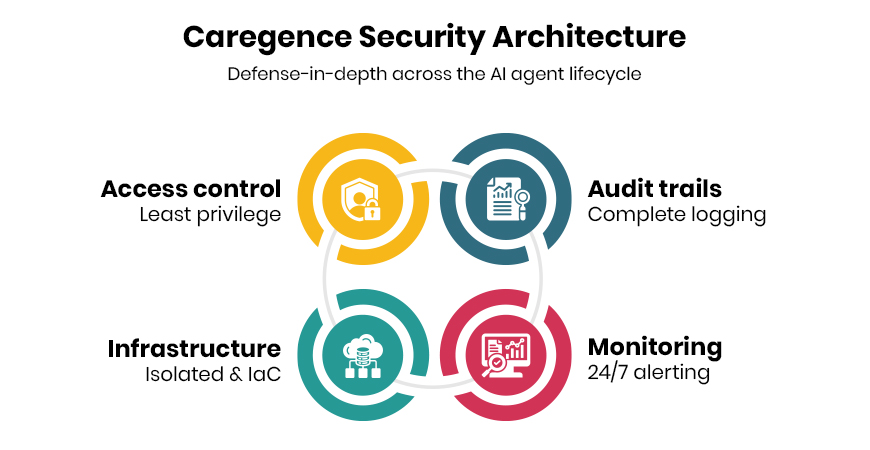
Caregence brings it together in one no-code, MCP-based agentic platform. Pre-built healthcare AI agents span access, clinical care, revenue cycle management, operations, care transitions, and engagement.
Connectors reach FHIR-native EHRs across acute and post-acute settings, plus API-based and custom integrations for systems without full FHIR and healthcare interoperability solutions for every environment. Secure communication; a conversational assistant; and full observability round it out, HIPAA-compliant by design.
The result: the AI-ready hospital is not a research project. It is an engagement with a partner who has built the hard parts before.
See how the department-by-department rollout plan looks for a hospital CIO piloting this today.

Frequently Asked Questions
What is an AI-ready hospital?
It’s not a new EHR. It’s the hospital’s existing EHR plus the two layers it was never built to be: a governed data foundation and a no-code agentic AI layer, joined by one conversational interface, without replacing or disrupting the EHR itself.
What are the two structural gaps in a typical hospital’s data setup?
First, the EHR was never the whole picture as it sits alongside lab, imaging, pharmacy, revenue cycle, coding, an ERP, a patient portal, and other systems that don’t stitch together on their own. Second, the EHR records work but rarely performs it: referrals, prior authorizations, and follow-ups, that still depend on manual human effort the chart never automates.
What is a master patient index, and what role does it play here?
It’s the mechanism that resolves duplicate patient identities into a single record. In this model, it sits inside the data foundation layer, alongside data quality enforcement, and feeds a unified Master Patient Index / Patient-360 view so leaders finally see one patient as one record instead of fragments across systems.
How does the conversational interface work?
It’s the shared entry point for both the foundation and the agentic layer. A user asks a question in plain language, gets an insight drawn from the hospital’s own data, and gets a recommended “next best action” the platform can then carry out, for example, a service-line leader asking why length-of-stay drifted, or a case manager asking which discharges are highest-risk today.
What does the agentic AI layer automate?
A no-code, drag-and-drop orchestration platform that acts across the care continuum and back office: automating access and intake, supporting clinical work and care coordination, tightening revenue and operations, and engaging patients directly — with every action logged, observable, and written back into the EHR.
Why does the discharge “transition of care” get called out specifically?
Because transition of care is still mostly manual, with respect to referrals to home health, hospice, palliative care, and home care largely faxed and keyed by hand. Readmissions and value-based contracts make what happens after discharge the hospital’s financial and clinical problem. But automating that hand-off closes the seam between the hospital and the next care setting.