Summary
Home health generates more clinical data per patient than almost any other care setting, yet readmissions that remain preventable, keep happening and caregiver turnover sits at 75%. The problem has never been data shortage but data visibility to see patient data as a whole.
The 360 Patient Journey and Next Best Action Agent from Inferenz fix this by converting fragmented multi-system data into a unified intelligence layer that tells the right care team member exactly what to do, before a crisis happens.
The Real Problem Is Not Data. It Is the Architecture.
I have sat across from enough home health executives to know that “we don’t have the data” is rarely the actual complaint. What they say, when you press them, is closer to: “We have all this data, and I still can’t tell you which patients are trending toward hospitalization this week.”
That is a data architecture problem, not an absence of some clinical system or tool.
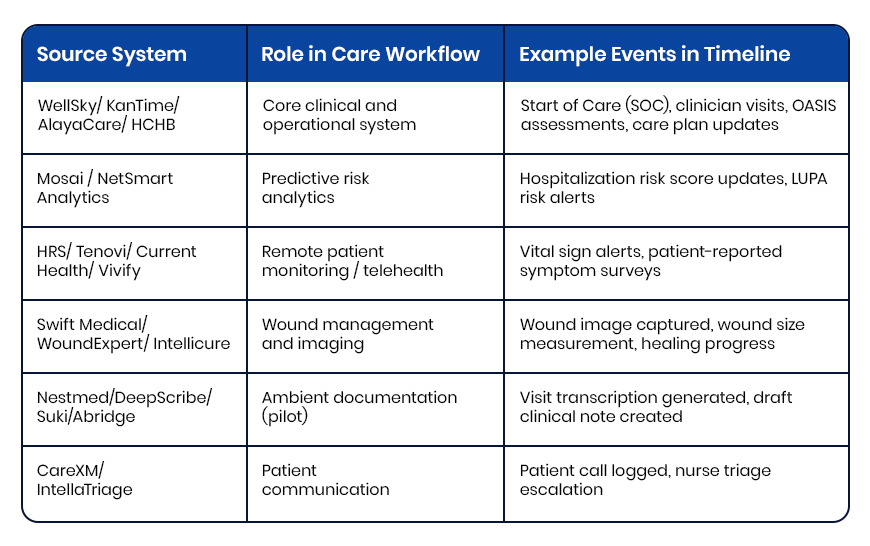
The average home health patient generates events across multiple, separate platforms in a single week.
- The EMR records visits and OASIS assessments.
- A remote monitoring platform logs vitals between visits.
- A predictive analytics tool recalculates hospitalization risk scores.
- A wound care system captures healing progression with images.
- An ambient documentation tool transcribes clinical conversations.
- An after-hours triage platform logs patient calls.
Every platform does its individual job well. Not one of them shows you the others.
The supervising care team managing 20-40 patients has no realistic way to correlate a vital spike on the remote monitoring platform with a risk score jump on the analytics tool and a missed visit in the EMR, because those three events exist in three separate systems, behind three separate logins, reviewed by three different people on three different timelines!
Check out how individual systems perform their individual roles in the care workflow:
The clinical pattern that would predict the next hospitalization is fully present in the data. It just cannot be read simultaneously.
What Clinical Fragmentation Actually Costs Home Health Agencies
This is where the stakes become concrete.
On patient outcomes
Hospital readmissions remain a major Medicare quality and cost concern, with CMS continuing to tie reimbursement penalties directly to excess 30-day readmission performance. In home health specifically, the deterioration signals that precede those hospitalizations: weight gain trends, rising vital thresholds, declining ADL scores, missed visits, are almost always present in clinical systems days before the ER visit.
On Medicare revenue
A 5% HHVBP payment swing equals $250,000 in annual revenue impact for a $5 million agency. That score is determined by 2024 performance data being calculated right now, as per expanded model. For most agencies, that performance data has never existed in a single unified view. The quality measures driving the score, including Preventable Hospitalization, Discharge Function Score, Discharge to Community, and Medication Management, are each shaped by whether care teams can see patient trajectory across systems in real time.
On workforce retention
Caregiver turnover sits at 75% annually,a staggering number! Nurses report spending up to two hours per shift navigating disconnected systems to assemble clinical context that should take two minutes. Documentation burden is a structural driver of attrition, not a cultural one. Reducing the time a clinician spends chasing information across platforms is a retention investment, not a workflow convenience.
What a Unified Patient Timeline Looks Like in Practice
Before describing how the 360 Patient Journey works technically, it helps to see what changes on a clinical level.
A supervising RN opens a single patient record. Without logging into anything else, she sees:
- Tuesday: Blood pressure 158/94, threshold exceeded, flagged moderate severity
- Tuesday: Patient survey reports increased fatigue and mild ankle swelling
- Three days prior: Hospitalization risk score elevated from 38 to 59, contributing factors flagged
- Four days prior: Diuretic dose increased per physician order
- Five days prior: RN visit completed, weight 3.2 lbs above baseline, physician notified
- Seven days prior: Start of Care, primary diagnosis CHF exacerbation
That sequence tells a complete clinical story. Rising weight. Medication adjustment. Risk score climbing. Fatigue worsening. Blood pressure spiking. The pattern is unmistakable when all events appear in order on one screen. Without a unified timeline, those same events sit across three platforms, reviewed by different people, connected by nobody.
This is what the 360 Patient Journey makes possible, and it is built entirely from data the organization was already generating. And then the Next Best Action Agent takes it further. It uses the visibility with a recommended next step attached. The right action, for the right patient, delivered to the right person before the pattern becomes a crisis. And it is built entirely from data the organization was already generating.

The 360 Patient Journey and the Next Best Action Agent: How They Work in Four Steps
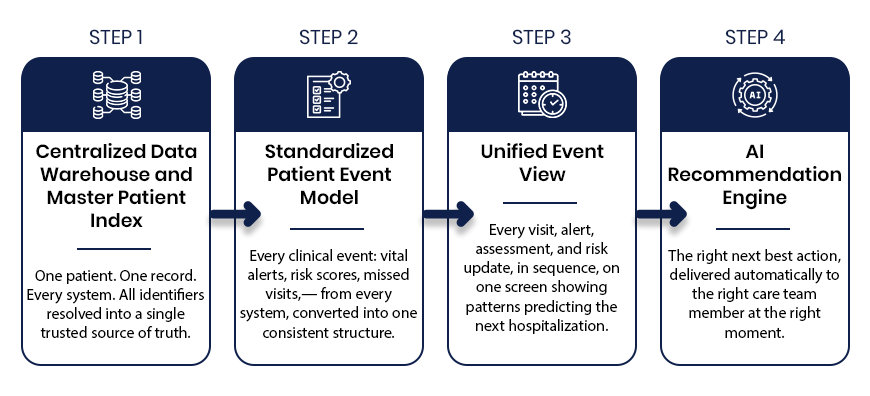
Step 1: Centralized Data Warehouse and Master Patient Index
What it solves: The same patient carries a different identifier in every system. A medical record number in the EMR. A device ID in remote monitoring. A Medicare beneficiary number in the analytics platform.
How it works: The Master Patient Index resolves every identifier, including name, date of birth, Medicare ID, and address, into one canonical patient record using probabilistic matching. One patient. One record. Across every system the organization runs.
Why it matters: Without identity resolution at this level, any downstream unification of clinical data is built on an unreliable foundation. Events get misassigned. Timelines become partial. Clinical decisions get made on incomplete records. The MPI is what makes everything that follows trustworthy.
Step 2: Standardized Patient Event Model
What it solves: Every clinical platform stores data in its own schema, its own timestamp format, its own taxonomy. A vital alert from a remote monitoring platform looks nothing like an OASIS completion from an EMR or a risk score update from a predictive analytics tool.
How it works: Every clinical event from every connected system gets converted into a single standardized structure: event type, timestamp, source system, clinical status, payload summary, and linked events. The care team does not log into six systems to understand one patient. The data arrives already translated into a common language.
Why it matters:For example, six systems with six formats produce six incomplete pictures. One standardized event model produces a complete one.
Step 3: Unified Event Timeline
What it solves: Even with data normalized, clinical teams need a way to see the full patient story in sequence, not as a database export.
How it works: Every normalized event displays in reverse chronological order on a single interface, flagged by severity, color-coded by source system, with linked event relationships visible briefly. The care team sees the complete longitudinal patient journey, from vital spikes and risk score changes to missed visits, wound progression, and after-hours calls, together and in the order they happened.
Why it matters: Patterns are only visible in sequence. The CHF patient whose weight gain, diuretic adjustment, risk score elevation, and vital spike appear as individual data points across three systems looks like four separate mild concerns. On a single unified timeline, they look like what they are: a hospitalization building over five days.
Step 4: AI Recommendation Engine and Next Best Action Agent
What it solves: A unified timeline shows what happened. The Next Best Action Agent tells care teams what to do about it.
How it works: The AI Recommendation Engine reads the complete patient timeline and delivers a specific, prioritized recommended action to the right care team member at the right moment. It surfaces patient summaries, risk drivers, and recommended action plans across every risk level, not just critical cases. The right nurse gets the right instruction automatically: schedule a visit today, escalate to the supervisory RN, request reauthorization before the unit gap widens.
Why it matters: Most clinical AI tools produce dashboards that require interpretation. The Next Best Action Agent produces decisions. There is a meaningful operational difference between a platform that shows a rising risk score and one that tells a specific person to make a specific call within the next four hours.
How Caregence Connects the Intelligence Layer to Clinical Workflows
The Next Best Action Agent runs on Caregence, Inferenz’s agentic AI platform built specifically for home health and hospice organizations. Caregence connects to existing EMR, payer, scheduling, EVV, and RCM systems without requiring agencies to replace a single platform they already use.
It provides the workflow infrastructure for deploying custom AI agents on top of unified patient data, including the Next Best Action Agent, with built-in governance, role-based access, and audit-ready communication tracking.
Think of Caregence as the operating system for proactive care. The 360 Patient Journey is an agent that provides the unified data foundation for visibility. It is based on Caregence that provides the AI agents that act on it, including the Next Best Action Agent.
The Measurable Impact: From Data Visibility to HHVBP Performance
Inferenz’s internal assessment of the 360 Patient Journey and Next Best Action Agent against the full HHVBP measure set found that this four-step process addresses up to 63% of HHVBP quality metrics directly.
The measures most influenced:
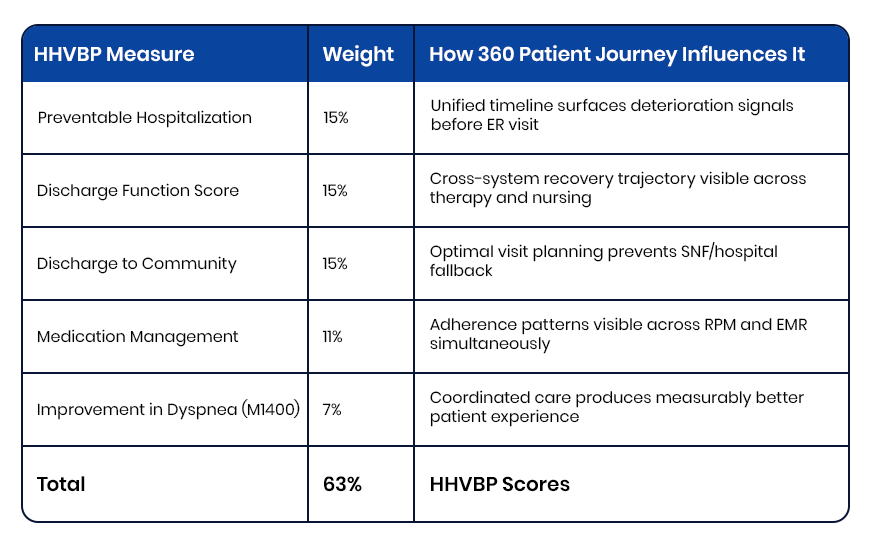
The agencies that improve HHVBP scores in 2026 will not do it by changing clinical protocols. They will do it by making existing clinical data visible in sequence, in context, and at the moment when action can still change the outcome.
The Bottom Line
Home health and hospice organizations are not data-poor. They are data-fragmented. Every signal needed to prevent the next hospitalization, protect HHVBP reimbursement, reduce documentation burden, and demonstrate outcomes to payers is already being generated inside the organization.
The 360 Patient Journey makes that data readable. Caregence makes it actionable. The Next Best Action Agent makes sure the right person acts on it before the window for intervention closes.
This is what Data to AI to ROI looks like in home health and hospice, built by Inferenz for organizations that cannot afford to keep losing $250,000 on a visibility problem they already have the data to solve.
Frequently Asked Questions
What is a unified patient timeline in home health?
A unified patient timeline is a single chronological view of every clinical event across a patient’s care episode, pulled from the EMR, remote monitoring, predictive analytics, wound care, and triage platforms, displayed in one interface without requiring multiple logins. Inferenz builds this through the 360 Patient Journey using a Master Patient Index and Standardized Patient Event Model.
How does a unified patient timeline help prevent hospitalizations in home health?
Deterioration signals: rising vitals, increasing risk scores, missed visits, declining ADL scores, almost always appear across multiple systems days before a hospitalization. A unified timeline places them in sequence on one screen so the care team sees the pattern before it becomes a crisis, not after.
What is a Next Best Action Agent in home health care?
A Next Best Action Agent is an AI system that reads the unified patient timeline and delivers a specific, prioritized clinical recommendation to the right care team member at the right moment. Where a dashboard shows information, the Next Best Action Agent delivers a decision which patient, what action, and when.
How do the 360 Patient Journey and Next Best Action Agent work together?
The 360 Patient Journey unifies data from every clinical system into a single patient timeline. The Next Best Action Agent reads that timeline and tells the care team exactly what to do next. Together they complete the full loop: data becomes visibility, visibility becomes action, action drives outcomes.
How does this improve HHVBP scores?
HHVBP’s highest-weighted measures: Preventable Hospitalization, Discharge Function Score, Discharge to Community, and Medication Management, all depend on early detection and proactive response. Inferenz’s internal assessment found this four-step process addresses up to 63% of HHVBP quality metrics directly.
What is Caregence and how does it power this solution?
Caregence is Inferenz’s agentic AI platform built for home health and hospice. It connects to existing EMR, payer, scheduling, and RCM systems and provides the workflow infrastructure for deploying the Next Best Action Agent on top of the unified data generated by the 360 Patient Journey.
Can this be implemented without replacing the existing EMR?
Yes. The 360 Patient Journey sits above existing systems, reading from them without replacing them. It connects to platforms including Homecare Homebase, Medalogix, Vivify, and Swift Medical through standard APIs and data integrations.
What is the difference between a risk dashboard and a Next Best Action Agent?
A dashboard shows a risk score and waits for a clinician to interpret it. The Next Best Action Agent reads the full patient timeline, interprets the risk in clinical context, and delivers a specific recommended action to a specific person, saving interpretation time that busy care teams rarely have.